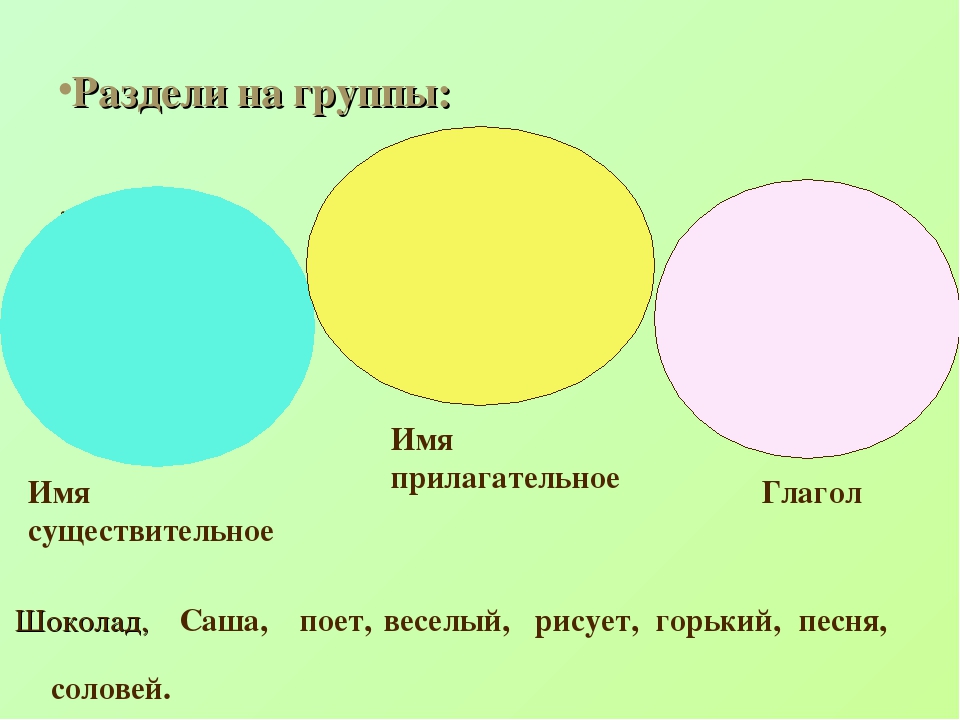
Всех людей можно разделить на 2 категории. На две группы. Первая группа — это те, которые спрашивают. Вторая группа — те, что отвечают. Одни задают вопросы. А другие молчат и лишь раздраженно хмурятся в ответ.
ПОХОЖИЕ ЦИТАТЫ
ПОХОЖИЕ ЦИТАТЫ
Мы все у Бога на ладони,
Татьяна Счастливая (2)
На одинаковых правах
И те, что в золотой короне
И те, что в порванных штанах…
В жизни возможны только две трагедии: первая — получить то, о чем мечтаешь, вторая — не получить.
Оскар Уайльд (500+)
Все люди делятся на две категории: те, с которыми легко, и также легко без них, и те, с которыми сложно, но невозможно без них.
Эрнест Хемингуэй (50+)
Правда жизни такова, что те люди, которые знают мало, говорят много, а те, которые знают много, предпочитают молчать.
Жан-Жак Руссо (100+)
Люди делятся на две половины. Одни, войдя в комнату, восклицают: «О, кого я вижу!»; другие: «А вот и я!»
Эбигайл Ван Берен (9)
Одни книги нужно попробовать на вкус, другие — проглотить, и лишь немногие — разжевать и переварить.
Фрэнсис Бэкон (100+)
Цените людей, которые приходят в те моменты, когда плохо не им, а вам.
Неизвестный автор (1000+)
Молчание молчанию рознь: одни молчат от непонимания, другие — слишком хорошо все понимают, и потому молчат.
Степан Балакин (20+)
Плохо живут те, которые лишь всю жизнь собираются жить.
Публий Сир (50+)

Верьте в свой бесконечный потенциал. Ваши единственные ограничения — это те, которые вы наложили на себя сами.
Рой Т. Беннет (1)
Все науки можно разделить на две группы
Все науки можно разделить на две группы – на физику и коллекционирование марок. Эрнест Резерфорд Физика – наука о наиболее общих законах природы. Она изучает простейшие формы движения материи и их взаимные превращения. Физика – наука экспериментальная, и эксперимент является одним из основных методов исследования в физике. Законы устанавливают связь между физическими величинами. 1
В настоящее время обязательной к применению является Международная система единиц System International – Система Интернациональная (СИ), которая состоит из: семи основных единиц метр, килограмм, секунда, ампер, кельвин, моль, кандела и двух дополнительных радиан и стерадиан.
Механика — часть физики, которая изучает закономерности механического движения и причины, вызывающие или изменяющие это движение. 3
Основные законы механики установлены итальянским физиком и астрономом Г. Галилеем (1564 – 1642) и окончательно сформулированы английским физиком И. Ньютоном (1643 – 1727). Механика Галилея и Ньютона называется классической, она рассматривает движение макроскопических тел со скоростями, значительно меньшими скорости света в вакууме. 4
Модели в механике Материальная точка – это тело, размерами, формой и внутренним строением которого в данной задаче можно пренебречь. Абсолютно твердое тело – это тело, которое не может деформироваться, и при всех условиях расстояние между любыми двумя точками этого тела остается постоянным. Сплошная среда – это модель, в которой не учитывается дискретное (молекулярное) строение; предполагается, что вещество непрерывно распределено в пространстве.
Кинематика изучает движение тел без учета их массы и действующих на них сил. 6
Механическое движение — это изменение относительного положения тел или их частей в пространстве с течением временем. 7
Всякое движение относительно! Относительность движения проявляется в том, что поведение любого движущегося тела может быть определено только по отношению к какому-то другому телу, которое называют телом отсчета. Траектория – это линия, вдоль которой движется материальная точка. 8
Система отсчета – это набор инструментов для исследования движения: Øтело отсчета, Øсвязанная с ним система координат, Øприбор измерения промежутков времени — часы. 9
Поступательное движение Вращательное движение Поступательным называется движение, при котором траектории всех точек тела одинаковы. Движение называется вращательным, если все точки тела движутся по окружностям, центры которых лежат на одной прямой, называемой осью вращения.
Поступательное движение Путь – это длина траектории. Перемещение – это вектор, равный разности радиусвекторов точки для двух разных моментов времени Вращательное движение Угол поворота – это угол, на который поворачивается радиус за время движения. 11
Поступательное движение Вращательное движение Скорость Угловая скорость — Средней скоростью за конечный промежуток времени называется отношение совершенного перемещения к этому промежутку времени Мгновенная скорость – это первая производная радиусвектора точки по времени это векторная величина, равная первой производной угла поворота по времени Вектор угловой скорости направлен вдоль оси вращения тела. 12
Поступательное движение Вектор мгновенной скорости направлен по касательной к траектории. Модуль мгновенной скорости Вращательное движение Для равномерного вращательного движения Период – это время одного полного оборота. Частота – это число Проекции вектора скорости на оси координат оборотов за единицу времени: Циклическая частота (или угловая скорость) – это число оборотов за 2 p секунд 13
Поступательное движение Вращательное движение Если известна зависимость v(t) то, проинтегрировав это выражение по времени, получим величину пути: w(t) то, проинтегрировав это выражение по времени, получим величину угла поворота: 14
Поступательное движение Ускорение — это первая производная скорости по времени или вторая производная радиусвектора по времени Вращательное движение Угловое ускорение — это первая производная угловой скорости по времени или вторая производная угла поворота по времени 15
Поступательное движение Тангенциальное ускорение характеризует изменение модуля скорости Нормальное ускорение характеризует изменение направления вектора скорости Векторы Вектор и коллинеарны.
Связь между линейными и угловыми величинами ( в радианах ) 17
Вопросы по теме КИНЕМАТИКА КИНЕМАТИК 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. Механическое движение – это… Система отсчета состоит из… Траектория – это … Путь – это… Перемещение – это… Какое движение называется поступательным? Какое движение называется вращательным? Скорость поступательного движения – это… Проекция скорости на ось ОХ – это… Угловая скорость – это… Чему равно и как направлено тангенциальное ускорение? Чему равно и как направлено нормальное ускорение? Чему равно и как направлено полное ускорение? Формула связи пути S и угла поворота . Формула связи скорости v и угловой скорости . Формула связи тангенциального ускорения a и углового ускорения . Формула связи нормального ускорения an и угловой скорости . 18
Динамика изучает механическое движение тел как следствие причины, вызывающей или изменяющей это движение. 19
19
В классической механике состояние системы определяется совокупностью значений координат и импульсов тел системы. . Основная задача динамики по заданным начальным значениям координат и импульса тела и действующим на него силам рассчитать координаты и импульс тела для любого другого момента времени. 20
Инерциальные системы отсчета Система отсчета называется инерциальной, если её тело отсчёта не испытывает внешние воздействия. В инерциальных системах отсчета тела находятся в состоянии покоя или прямолинейного и равномерного движения до тех пор, пока на них не подействуют другие тела. Однородность пространства и времени означает, что наблюдаемые физические свойства и явления одинаковы в любой точке пространства и в любой момент времени. Изотропность пространства предполагает, что в пространстве все направления равноправны и физические явления в замкнутых системах не изменяются при ее повороте в пространстве. 21
ПОСТУПАТЕЛЬНОЕ ДВИЖЕНИЕ Сила — вектор, характеризующий степень воздействия на тело других тел. ВРАЩАТЕЛЬНОЕ ДВИЖЕНИЕ О Моментом силы относительно оси Z называется скалярная величина MZ , равная произведению проекции силы на плоскость, перпендикулярную оси вращения, на плечо этой силы относительно данной оси: Равнодействующая сила: [F ] = Н [MZ ] = Н м 22
ВРАЩАТЕЛЬНОЕ ДВИЖЕНИЕ О Моментом силы относительно оси Z называется скалярная величина MZ , равная произведению проекции силы на плоскость, перпендикулярную оси вращения, на плечо этой силы относительно данной оси: Равнодействующая сила: [F ] = Н [MZ ] = Н м 22
ПОСТУПАТЕЛЬНОЕ ДВИЖЕНИЕ Точка пересечения линий действия сил, вызывающих поступательное движение тела, называется центром инерции данного тела. ВРАЩАТЕЛЬНОЕ ДВИЖЕНИЕ Плечом силы относительно оси называется расстояние между линией действия силы и данной осью. Результирующий момент силы: 23
ПОСТУПАТЕЛЬНОЕ ДВИЖЕНИЕ ВРАЩАТЕЛЬНОЕ ДВИЖЕНИЕ Масса – мера инертности тела в поступательном движении. Момент инерции – мера инертности тела во вращательном движении. Инертностью называется свойство тел сохранять состояние покоя или прямолинейного и равномерного движения. Моментом инерции материальной точки называется произведение массы этой точки на квадрат расстояния от точки до оси вращения: Масса – величина аддитивная: Момент инерции – величина аддитивная: [ m ] = кг [ J ] = кг м 2 24
ПОСТУПАТЕЛЬНОЕ ДВИЖЕНИЕ Импульс материальной точки равен произведению массы точки на ее скорость: ВРАЩАТЕЛЬНОЕ ДВИЖЕНИЕ Момент импульса материальной точки равен произведению модуля импульса на расстояние от точки до оси: Или Момент импульса материальной точки равен произведению момента инерции на угловую скорость точки: [ p ] = кг м/с [ L ] = кг м 2/с 25
ПОСТУПАТЕЛЬНОЕ ДВИЖЕНИЕ ВРАЩАТЕЛЬНОЕ ДВИЖЕНИЕ Сила и импульс. Второй закон Ньютона Момент сил и момент импульса [ F ] = кг м/с²=H [ M ] = кг м²/с²=H м 26
Второй закон Ньютона Момент сил и момент импульса [ F ] = кг м/с²=H [ M ] = кг м²/с²=H м 26
ПОСТУПАТЕЛЬНОЕ ДВИЖЕНИЕ ВРАЩАТЕЛЬНОЕ ДВИЖЕНИЕ 1687 год Первый закон Ньютона Тело покоится или движется прямолинейно и равномерно, пока другое тело не изменит это состояние: пока Тело вращается равномерно или покоится, пока результирующий момент сил, действующих на тело относительно оси вращения, равен нулю: пока 27
ПОСТУПАТЕЛЬНОЕ ДВИЖЕНИЕ ВРАЩАТЕЛЬНОЕ ДВИЖЕНИЕ Основное уравнение динамики поступательного движения: Основное уравнение динамики вращательного движения: равнодействующая внешних сил равна произведению массы на ускорение тела. суммарный момент внешних сил равен произведению момента инерции на угловое ускорение тела. скорость изменения импульса тела равнодействующей сил, действующих на тело. скорость изменения момента импульса равна результирующему моменту силы, действующему на тело. 28
ПОСТУПАТЕЛЬНОЕ ДВИЖЕНИЕ Третий закон Ньютона: силы взаимодействия двух тел равны по модулю, противоположны по направлению и действуют вдоль прямой, соединяющей эти тела: ВРАЩАТЕЛЬНОЕ ДВИЖЕНИЕ Правило моментов утверждает, что если рычаг находится в равновесии (не вращается), то сумма моментов сил, поворачивающих рычаг против часовой стрелки, равна сумме моментов сил, поворачивающих рычаг по часовой стрелке. Силы взаимодействия имеют одинаковую природу, появляются и исчезают одновременно. 29
Силы взаимодействия имеют одинаковую природу, появляются и исчезают одновременно. 29
ПОСТУПАТЕЛЬНОЕ ДВИЖЕНИЕ Система, для которой равнодействующая внешних сил равна нулю, называется замкнутой (или изолированной). Закон сохранения импульса суммарный импульс тел замкнутой системы не изменяется с течением времени: ВРАЩАТЕЛЬНОЕ ДВИЖЕНИЕ Закон сохранения момента импульса суммарный момент импульса тел замкнутой системы не изменяется с течением времени: Закон сохранения момента импульса является проявлением свойства изотропности пространства. Закон сохранения импульса является проявлением свойства однородности пространства. 30
Вопросы по теме ДИНАМИКА 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. Какая система отсчета называется инерциальной? Что такое сила? Что такое результирующая сила? Что такое момент силы? Что такое плечо силы? Что такое масса? Что такое момент инерции? Чему равен момент инерции материальной точки? Что называется импульсом материальной точки? Что называется моментом импульса материальной точки? О чем говорит первый закон Ньютона? О чем говорит второй закон Ньютона? Запишите основное уравнение динамики поступательного движения. Запишите основное уравнение динамики вращательного движения. О чем говорит третий закон Ньютона? Сформулируйте закон сохранения импульса. Сформулируйте закон сохранения момента импульса. 31
Запишите основное уравнение динамики вращательного движения. О чем говорит третий закон Ньютона? Сформулируйте закон сохранения импульса. Сформулируйте закон сохранения момента импульса. 31
| Режущий инструмент, инструментальная оснастка и приспособления / Cutting tools, tooling system and workholding SANDVIK COROMANT | Руководство SANDVIK COROMANT 2010 по металлообработке (Всего 800 стр.) | ||||||||
152 SANDVIK COROMANT 2010 Руководство по металлообработке Точение Фрезерование Сверление Стр.A146 | ||||||||
Все режущие инструментальные материалы можно разделить на две группы Основные и дополнительные Марки сплавов для токарной обработки представлены на Все режущие инструментальные материалы можно разделить на две группы Основные и дополнительные Марки сплавов для токарной обработки представлены на диаграмме ISO ANSI в зависимости от их износостойкости и прочности Сплавы основной группы имеют достаточно широкую область применения и их следует рассматривать в качестве первого выбора. | ||||||||
См.также / See also : | ||||||||
Соотношение твердостей Таблица / Hardness equivalent table | Аналоги марок стали / Workpiece material conversion table | |||||||
Отклонение размера детали / Fit tolerance table | Перевод оборотов в скорость / Surface speed to RPM conversion | |||||||
Диаметр под резьбу / Tap drill sizes | Виды резьбы в машиностроении / Thread types and applications | |||||||
Дюймы в мм Таблица / Inches to mm Conversion table | Современные инструментальные материалы / Cutting tool materials | |||||||
| Руководства по металлообработке и каталоги инструмента SANDVIK COROMANT | ||||||||
| | ||||||||
Каталог SANDVIK COROMANT 2017 Инструмент токарный и оснастка (656 страниц) | Каталог SANDVIK COROMANT 2017 Инструмент вращающийся и оснастка (515 страниц) | Каталог SANDVIK COROMANT 2016 Металлорежущий цельный инструмент (866 страниц) | Каталог SANDVIK COROMANT 2016 Обработка глубоких отверстий (226 страниц) | Каталог SANDVIK COROMANT 2015 Токарные инструменты (1253 страницы) | Каталог SANDVIK COROMANT 2015 Вращающиеся инструменты (1500 страниц) | |||
Каталог SANDVIK COROMANT 2015 Комплектующие для инструмента (670 страниц) | Каталог SANDVIK COROMANT 2015 Специальный инструмент (163 страницы) | Каталог SANDVIK COROMANT 2001 Вращающиеся инструменты (751 страницы) | Каталог SANDVIK COROMANT 2000 Токарный инструмент (573 страницы) | Каталог SANDVIK COROMANT 2017 Инструмент Сандвик-МКТС (104 страницы) | Каталог SANDVIK COROMANT 2000 Инструмент и сменные пластины Сандвик МКТС (172 страницы) | |||
Руководство SANDVIK COROMANT 2010 по металлообработке (800 страниц) | Каталог SANDVIK COROMANT 2010 CoroKey Режущий инструмент (216 страниц) | Пособие SANDVIK COROMANT 2009 Обработка металлов резанием (359 страниц) | Каталог SANDVIK COROMANT 2006 CoroKey Металлорежущий инструмент (195 страниц) | Руководство SANDVIK COROMANT 2005 по обработке металлов резанием (564 страницы) | Учебник SANDVIK COROMANT 2003 Обработка резанием (301 страница) | |||
Каталоги инструмента и оснастки для металлообработки на станках / | ||||||||
Руководство SANDVIK COROMANT 2010 по металлообработке (Всего 800 стр. ) ) | ||||||||
| | 149 Металлорежущий многофункциональный шведский инструмент для точения отрезки обработки канавок и резьбонарезания Многопозиционные сборные адаптеры Sa | 150 Металлорежущий многофункциональный инструмент Sandvik Coromant CoroPlex MT для обрабатывающих центров с числовым программным управлением Области пр | 151 Резцовые вставки со сменными режущими твердосплавными пластинами в первую очередь предназначены для применения в многоинструментальных наладках и о | 153 Описание сплавов Сандвик для токарной обработки стали и ковкого чугуна которые дают сливную стружку Основные и дополнительные марки Области примене | 154 Основные и дополнительные марки сплавов Sandvik для точения нержавеющей стали Группа обрабатываемости по ISO M Основные сплавы GC1025 GC2015 GC 111 | 155 Инструментальные режущие материалы для токарной обработки чугуна Чрезвычайно твердая марка кубического нитрида бора Sandvik CB50 CB7050 Область при | ||
— — | ||||||||
 Дополнительные сплавы предназначены для расширения области применения сплавов основной группы и зачастую выступают в качестве их достойной альтернативы. Буквенное обозначение инструментальных материалов Твердые сплавы HW Твердые сплавы без покрытия содержащие в основном карбид вольфрама (WC). HT Безвольфрамовые твердые сплавы без покрытия (керметы) содержащие в основном карбиды (TIC) или нитриды (TIN) титана или и те и другие вместе. Керамика CA Окисная металлокерамика состоящая из окиси алюминия (AI2O3). CM Смешанная керамика на основе оксида алюминия (AI2O3) но содержащая также и другие компоненты. CN Нитридная керамика содержащая в основном нитрид кремния (Si3N4). CC Вышеперечисленные керамические материалы но с покрытием. Алмаз DP Поликристаллический алмаз 1) Нитриды бора BN Кубический нитрид бора 1) i) Поликристаллический алмаз и кубический нитрид бора также называют сверхтвердыми режущими материалами. HC Вышеперечисленные твердые сплавы но с покрытием. Положение и форма диаграммы инструментального материала определяет рекомендуемую область применения.
Дополнительные сплавы предназначены для расширения области применения сплавов основной группы и зачастую выступают в качестве их достойной альтернативы. Буквенное обозначение инструментальных материалов Твердые сплавы HW Твердые сплавы без покрытия содержащие в основном карбид вольфрама (WC). HT Безвольфрамовые твердые сплавы без покрытия (керметы) содержащие в основном карбиды (TIC) или нитриды (TIN) титана или и те и другие вместе. Керамика CA Окисная металлокерамика состоящая из окиси алюминия (AI2O3). CM Смешанная керамика на основе оксида алюминия (AI2O3) но содержащая также и другие компоненты. CN Нитридная керамика содержащая в основном нитрид кремния (Si3N4). CC Вышеперечисленные керамические материалы но с покрытием. Алмаз DP Поликристаллический алмаз 1) Нитриды бора BN Кубический нитрид бора 1) i) Поликристаллический алмаз и кубический нитрид бора также называют сверхтвердыми режущими материалами. HC Вышеперечисленные твердые сплавы но с покрытием. Положение и форма диаграммы инструментального материала определяет рекомендуемую область применения. Основной сплав Дополнительный сплав Центр области применения Рекомендуемая область применения к Износостойкость Прочность ISO P Сталь и ISO M Нержавеющая сталь ISO K Чугун и ISO N Цветные металлы S ISO S Жаропрочные сплавы ISO H Закаленные материалы A 146 SANDVIK Точение Информация о сплавах Информация о сплавах Современные инструментальные материалы очень разнообразны и их развитие постоянно продолжается. При этом модернизации подвергаются не только сами инструментальные материалы но и технологии их изготовления. Результатом этих процессов является широкий ассортимент высокопроизводительного инструмента для различных типов операций.
Основной сплав Дополнительный сплав Центр области применения Рекомендуемая область применения к Износостойкость Прочность ISO P Сталь и ISO M Нержавеющая сталь ISO K Чугун и ISO N Цветные металлы S ISO S Жаропрочные сплавы ISO H Закаленные материалы A 146 SANDVIK Точение Информация о сплавах Информация о сплавах Современные инструментальные материалы очень разнообразны и их развитие постоянно продолжается. При этом модернизации подвергаются не только сами инструментальные материалы но и технологии их изготовления. Результатом этих процессов является широкий ассортимент высокопроизводительного инструмента для различных типов операций.Разделение ячейки
Вам может потребоваться разделить определенную ячейку на две небольшие, расположенные в одном столбце. К сожалению, такая возможность в Excel не поддерживается. Вместо этого вы можете создать новый столбец рядом с тем, в котором расположена необходимая ячейка, а затем разделить ее. Кроме того, содержимое ячейки можно разделить на несколько смежных ячеек.
К сожалению, такая возможность в Excel не поддерживается. Вместо этого вы можете создать новый столбец рядом с тем, в котором расположена необходимая ячейка, а затем разделить ее. Кроме того, содержимое ячейки можно разделить на несколько смежных ячеек.
Пример разделения ячеек:
Разделение содержимого ячейки на несколько ячеек
-
Выделите одну или несколько ячеек, которые хотите разделить.
Важно: При разделении ячейки ее содержимое заменит данные из следующей ячейки, поэтому освободите достаточное пространство на листе.
-
На вкладке Данные в группе Работа с данными нажмите кнопку Текст по столбцам. Откроется Мастер распределения текста по столбцам.
-
Установите переключатель С разделителями, если выбран другой вариант, и нажмите кнопку Далее.

-
Выберите один или несколько разделителей, чтобы задать места, в которых произойдет разделение ячейки. В области Образец разбора данных можно посмотреть на предполагаемые результаты разделения. Нажмите кнопку Далее.
-
В области Формат данных столбца выберите формат данных для новых столбцов. По умолчанию в них будет использоваться такой же формат данных, как и в исходной ячейке. Нажмите кнопку Готово.

См. также
Объединение и отмена объединения ячеек
Объединение и разделение ячеек или данных
Международное полицейское взаимодействие: поиск новых подходов
О сегодняшних приоритетных направлениях международного полицейского взаимодействия и его правовых основах рассказывает первый заместитель начальника Управления международного сотрудничества МВД России кандидат юридических наук полковник внутренней службы Владимир Караиванов.
В основе задач, стоящих перед органами внутренних дел Российской Федерации в сфере международного сотрудничества, лежат документы стратегического планирования, в частности Концепция внешней политики Российской Федерации и Стратегия национальной безопасности Российской Федерации. Они развиваются и детализируются в поручениях Президента Российской Федерации, Правительства Российской Федерации, решениях Совета Безопасности Российской Федерации и руководства Министерства внутренних дел Российской Федерации.
Все задачи можно разделить на две универсальные группы. Первая связана с организационно-правовым обеспечением контактов и переговоров с компетентными органами иностранных государств. Вторая – с осуществлением практических мероприятий по реализации достигнутых договорённостей с зарубежными партнёрами.
Очевидна необходимость поиска новых подходов к решению проблем борьбы с преступностью: незаконным оборотом наркотиков, экстремизмом и терроризмом, другими опасными проявлениями транснациональной преступности.
Высокий уровень сотрудничества традиционно сохраняется с Китаем, Вьетнамом, Республикой Корея, Ираном, Израилем, Индией, Монголией, Никарагуа, Сербией и другими странами. Несмотря на известные внешнеполитические факторы, удалось найти и новые взаимовыгодные точки соприкосновения с правоохранительными органами Западной Европы. На регулярно организуемых заседаниях двусторонних рабочих групп (с МВД Австрии, Германии, Италии, Испании, Финляндии и ряда других государств) рассматривается обширная антикриминальная повестка, включающая в себя такие актуальные и перспективные направления сотрудничества, как пресечение деятельности лидеров транснациональных преступных сообществ и организаций; инициация обмена сведениями о финансовых операциях, направленных на легализацию преступных доходов; совершенствование комплекса мер по противодействию угрозам экстремистского и террористического характера; выявление радикально настроенных лиц в миграционных потоках; согласование программ совместных действий по борьбе с новыми и уже известными, но трансформирующимися видами преступности (например, незаконным оборотом наркотиков, мошенничеством).
Подготовке и практической реализации указанных направлений способствует активный информационный обмен, в том числе через разветвлённую сеть сотрудников загранаппарата МВД России и полицейских атташе (офицеров связи), аккредитованных при дипломатических учреждениях зарубежных стран в Российской Федерации.
Через загранаппарат МВД России, офицеров связи, по дипломатическим каналам, а также через прямые контакты у иностранных партнёров уточняется статус рассмотрения запросов об оказании содействия и запросов о правовой помощи по уголовным делам (за 2020 год адресовано около 2,5 тысяч следственных поручений, получено на исполнение – порядка 7 тысяч). Прорабатываются альтернативные механизмы процедур выдачи преступников. Так, представителями МВД России выработан алгоритм депортации находящихся в международном розыске лиц в страны гражданской принадлежности (с 2020 года – уже около 10 фигурантов).
В последние 2 года в связи с пандемией COVID-19 на первый план выдвинулась проблема безопасности виртуального пространства.
При координирующей роли Совета Безопасности Российской Федерации и МИД России представители министерства на регулярной основе принимают участие в двусторонних и многосторонних экспертных консультациях в области МИБ.
Встреча Владимира Караиванова с начальником Оперативных подразделений Полиции Главного Управления Полиции Испании генеральным комиссаром Хосе Мигелем Руисом Игускисом
Россия традиционно рассматривает три основных направления угроз МИБ – военно-политического, террористического и криминального характера. Борьба с преступностью в глобальном информационном пространстве осложняется отсутствием полноценной международно-правовой базы сотрудничества государств. Российская Федерация последовательно выступает с инициативой разработки под эгидой Организации Объединённых Наций (ООН) универсальной конвенции по противодействию информационной преступности: поддержаны предложенные Россией меры по борьбе с преступностью в сфере информационно-коммуникационных технологий (ИКТ) и создан Специальный межправительственный комитет экспертов по разработке под эгидой ООН всеобъемлющей международной конвенции о противодействии использованию ИКТ в преступных целях, в 2020–2021 годах запущена его работа.
Российская Федерация последовательно выступает с инициативой разработки под эгидой Организации Объединённых Наций (ООН) универсальной конвенции по противодействию информационной преступности: поддержаны предложенные Россией меры по борьбе с преступностью в сфере информационно-коммуникационных технологий (ИКТ) и создан Специальный межправительственный комитет экспертов по разработке под эгидой ООН всеобъемлющей международной конвенции о противодействии использованию ИКТ в преступных целях, в 2020–2021 годах запущена его работа.
В разработке этого документа на межведомственной основе под эгидой Генеральной прокуратуры Российской Федерации принимали активное участие эксперты министерства.
МВД России провело большую работу по присоединению к Соглашению о сотрудничестве государств – участников Содружества Независимых Государств в борьбе с преступлениями в сфере информационных технологий от 28 сентября 2018 года, правовой инструментарий которого позволит обеспечить правоохранительным органам стран Содружества эффективную борьбу с «компьютерными» преступлениями.
Согласно отчёту Всемирного экономического форума о глобальных рисках 2020 года в течение последних лет преступления в сфере ИТ регулярно входят в число пяти наиболее опасных мировых угроз. Расследование и раскрытие преступлений о дистанционных хищениях нуждаются в выработке единого алгоритма действий как на этапе проверки заявления и сообщения о преступлении, так и на первоначальном этапе расследования. При утечке информации, нарушении критической инфраструктуры объектов информатизации максимально важна оперативность реагирования и легитимность проводимых мероприятий, особенно если речь идёт о трансграничной преступности в сфере ИКТ. При этом особое значение имеет сохранение конфиденциальности персональных данных.
Приоритетными также являются следующие направления работы: повышение эффективности сотрудничества с правоохранительными и миграционными органами иностранных государств, международными организациями по различным направлениям оперативно-служебной деятельности на основе укрепления и развития правовой базы международного взаимодействия и приграничного сотрудничества; разработка и заключение двусторонних и многосторонних международных договоров Российской Федерации в сфере внутренних дел, а также обеспечение вступления их в силу; участие в разработке модельных законов в рамках СНГ, Организации Договора о коллективной безопасности (ОДКБ) в сфере деятельности, относящейся к компетенции МВД России.
Так, с момента образования УМС МВД России ведётся активная работа в сфере нормативно-правового обеспечения вопросов международного сотрудничества. С 2019 года по настоящее время подписано порядка 20 международных договоров, 10 из которых – соглашения в сфере укрепления межведомственного взаимодействия по различным актуальным направлениям деятельности с компетентными органами стран дальнего зарубежья, в том числе Государства Катар, Многонационального Государства Боливия, Федеративной Республики Бразилия, Республики Нигер.
В числе наиболее значимых, позволяющих в перспективе осуществлять трансграничный обмен информацией по защищённым каналам связи, следует отметить заключённые по линии министерства межправительственные соглашения с республиками Узбекистан, Армения и Таджикистан. Большой объём работы проделан в ходе подготовки и подписания 5 договоров, направленных на укрепление взаимодействия с республиками Абхазия и Южная Осетия, в том числе по линии постоянно действующих совместных информационно-координационных центров органов внутренних дел.
Активно ведётся работа над многосторонними актами – проектами Соглашения об обмене и защите секретной информации в рамках Центральноазиатского регионального информационного координационного центра по борьбе с незаконным оборотом наркотических средств, психотропных веществ и их прекурсоров и Протокола о сотрудничестве в области борьбы с незаконным оборотом наркотических средств, психотропных веществ и их прекурсоров на Каспийском море к Соглашению о сотрудничестве в сфере безопасности на Каспийском море от 18 ноября 2010 года.
Как упоминалось ранее, во многих странах при посольствах Российской Федерации работают представители МВД России. В настоящее время министерство располагает загранаппаратом, представленным в 30 государствах, в том числе в США, Франции, Германии, Австрии, Швейцарии, Турции, Китае, Афганистане, Индии, Израиле, Испании, ЮАР и ряде других. В работе представительств, дислоцированных в Армении, Киргизии, Латвии, Молдове, Таджикистане, Туркменистане, Узбекистане, Украине, основное внимание уделяется организации процесса добровольного переселения соотечественников в Россию. Инструментарий загранаппарата позволяет продвигать российские позиции и инициативы за рубежом, осуществлять сбор и анализ информации о складывающейся обстановке в конкретных странах и мире в целом, тенденциях противодействия преступности, непосредственно участвовать в реализации различных запросов, а также процедурах выдачи лиц, находящихся в розыске. Почти за четверть века загранаппарат МВД России стал неотъемлемой частью механизма противодействия транснациональной преступности (в том числе экстремизму и терроризму, незаконному обороту наркотических средств, психотропных веществ) и регулирования миграционных процессов.
Инструментарий загранаппарата позволяет продвигать российские позиции и инициативы за рубежом, осуществлять сбор и анализ информации о складывающейся обстановке в конкретных странах и мире в целом, тенденциях противодействия преступности, непосредственно участвовать в реализации различных запросов, а также процедурах выдачи лиц, находящихся в розыске. Почти за четверть века загранаппарат МВД России стал неотъемлемой частью механизма противодействия транснациональной преступности (в том числе экстремизму и терроризму, незаконному обороту наркотических средств, психотропных веществ) и регулирования миграционных процессов.
Сотрудник органов внутренних дел Российской Федерации полковник юстиции Юлия Ким на медальном параде в Миссии ООН по стабилизации в Демократической Республике Конго, приуроченном к Международному дню миротворцев ООН
На фоне расширения в последние десятилетия международного миротворчества представители ведомства принимают активное участие в миссиях ООН и Организации по безопасности и сотрудничеству в Европе (ОБСЕ). Наши сотрудники представлены на должностях тактических и оперативных руководителей, а также экспертов в составе миротворческих полицейских сил и несут службу на территории Македонии, Узбекистана, Киргизии, Украины, Косово, Конго, Кипра, Южного Судана, Судана, Абьей, Италии. Задачи, поставленные перед нашим контингентом, подчас выполняются в условиях, близких к боевым или опасным для жизни и здоровья.
Наши сотрудники представлены на должностях тактических и оперативных руководителей, а также экспертов в составе миротворческих полицейских сил и несут службу на территории Македонии, Узбекистана, Киргизии, Украины, Косово, Конго, Кипра, Южного Судана, Судана, Абьей, Италии. Задачи, поставленные перед нашим контингентом, подчас выполняются в условиях, близких к боевым или опасным для жизни и здоровья.
Министерство внутренних дел Российской Федерации является головным российским ведомством по участию в мероприятиях, проводимых в рамках КТОП. С прошлого года запущен механизм обзора выполнения данной Конвенции государствами-участниками, в ходе которого оценивается эффективность её реализации и имплементация положений её статей в национальное законодательство. Согласно прошедшей жеребьёвке с 2021-го по 2023-й год Россия выступает в качестве обозреваемого государства, а в период с 2022-го по 2024-й – в качестве обозревающего.
Согласно прошедшей жеребьёвке с 2021-го по 2023-й год Россия выступает в качестве обозреваемого государства, а в период с 2022-го по 2024-й – в качестве обозревающего.
Важной является деятельность в рамках Рабочей группы Организации Черноморского экономического сотрудничества по борьбе с преступностью, особенно в её организованных формах (ЧЭС). Она направлена на содействие правоохранительным органам государств – членов ЧЭС в противодействии торговле людьми и террористической деятельности, своевременному реагированию на новые вызовы и угрозы на основе оценки тенденций транснациональной преступности в Черноморском регионе.
В 2021 году МВД России является координатором в данной группе. Во второй половине 2022 года к Российской Федерации перейдёт председательство в ЧЭС. Министерство видит в этом возможность внести вклад в придание дополнительного импульса в деятельности ЧЭС по борьбе с организованной преступностью, укрепить авторитет Российской Федерации на этом направлении, сделать акцент на практических мероприятиях, снизив тем самым градус политизации и заложив вектор общерегионального сотрудничества на последующие годы.
Работа в Казани, поиск персонала и публикация вакансий
Работа в Казани — это большой выбор открытых позиций в различных отраслях деятельности: от сотрудников сферы обслуживания до руководящих должностей в крупных компаниях.
Большинство соискателей в Казани можно условно разделить на четыре группы. Первая — вчерашние выпускники учебных заведений без опыта работы; вторая — специалисты, которые хотят переквалифицироваться; третья — сотрудники, оказавшиеся в карьерном тупике; четвертая — соискатели, основной целью которых является материальный заработок.
Показать полностью
Первая категория более свободна в своем выборе: они ориентируются в первую очередь на собственные устремления. Главный враг таких соискателей — завышенная самооценка и амбиции. Однако стоит подойти к выбору работы без юношеского максимализма — и нужная вакансия найдется быстро. Вторая категория — люди, решившие в корне изменить вид деятельности. Часто это связано с тем, что предыдущий опыт работ их не устраивал. Рекрутеры советуют таким соискателям больше ориентироваться на психологическую предрасположенность. Если уж вы начинаете с нуля — делайте это на любимом поприще.
Часто это связано с тем, что предыдущий опыт работ их не устраивал. Рекрутеры советуют таким соискателям больше ориентироваться на психологическую предрасположенность. Если уж вы начинаете с нуля — делайте это на любимом поприще.
К третьей группе соискателей относятся специалисты, которые многого добились и обнаружили, что на старом месте рост просто невозможен. Нередко они ищут работу, еще не уволившись, и получают выгодные предложения заранее. В четвертой категории — соискатели, основной целью которых является материальный заработок, а профессиональный статус стоит у них на втором месте. Рынок труда изобилует предложениями для данной категории.
Независимо от того, к какой группе соискателей вы относитесь, с помощью сервисов HeadHunter вы без труда отыщете предложение о работе, удовлетворяющее вашим потребностям.
Удобный поиск, система уведомлений и рассылки позволяют сократить время и силы, которые обычно уходят на выбор подходящей вакансии. Первый шаг к карьере — заполните форму резюме и разместите его. Затем просто откликайтесь на вакансии интересных компаний и получайте приглашения от работодателей. Нет времени следить за появлением новых предложений на сайте? Используйте сервис рассылки и уведомлений. Система сама присылает информацию о подходящих вакансиях и работе в Казани на вашу электронную почту, что существенно экономит время.
Затем просто откликайтесь на вакансии интересных компаний и получайте приглашения от работодателей. Нет времени следить за появлением новых предложений на сайте? Используйте сервис рассылки и уведомлений. Система сама присылает информацию о подходящих вакансиях и работе в Казани на вашу электронную почту, что существенно экономит время.
Большинство услуг для соискателя абсолютно бесплатны. Обновления происходят регулярно, превращая поиск работы в увлекательное времяпровождение.
Петрушка: польза, вред, калорийность | РБК Стиль
Петрушка укрепляет иммунную систему, улучшает здоровье костей и глаз, полезна для работы почек, сердца и мозга. Пережевывание нескольких листиков поможет быстро освежить дыхание, а отвары и масла на основе этого растения используют для ухода за кожей и волосами. Разбираемся с экспертами — дерматологом и нутрициологом — во всех полезных свойствах этого продукта.
Материал прокомментировали: Александра Разаренова, врач-диетолог, нутрициолог, терапевт, член Российского союза нутрициологов, диетологов и специалистов пищевой индустрии; Юлия Галлямова, д.м.н., профессор кафедры дерматовенерологии и косметологии ФГОУ ДПО «Российская медицинская академия непрерывного профессионального образования»
Что такое петрушка
По одной из версий, в русском языке «петрушка» появилась через заимствование слова, которое происходит от латинского petroselinum («горный сельдерей»)
© Kathas_Fotos/Pixabay
Петрушка — это цветущее растение ярко-зеленого цвета, с мягким и слегка горьковатым вкусом. С научной точки зрения она известна как Petroselinum и относится к семейству зонтичных. Существуют два основных вида петрушки, отличающихся только внешним видом: кудрявая, или «французская», и обычная, с плоским листом, или «итальянская». Еще одной разновидностью растения можно считать мицубу — японский аналог, с плоскими листьями, по вкусу и внешнему виду похожий на европейское растение.
Еще одной разновидностью растения можно считать мицубу — японский аналог, с плоскими листьями, по вкусу и внешнему виду похожий на европейское растение.
Петрушку готовят в свежем и сушеном виде. Ее добавляют как специю, подают отдельной легкой закуской и используют для украшения готовых блюд. Есть можно все части «зелени»: побеги, стебель и корень. Последний готовят, как и другие корнеплоды, например морковь и репу.
Благодаря простому уходу петрушку можно выращивать в домашних условиях круглый год.
Пищевая ценность
Петрушка — низкокалорийный продукт, в ней много полезных веществ, среди которых витамины K, A и C.
Пищевой профиль (на 100 г) [1]:
- Калории — 36
- Белки — 2,9 г
- Жиры — 0,79 г
- Углеводы — 6,3 г
- Клетчатка — 3,3 г
- Вода — 88 г
Витамины
- Витамин С — 133 мг
- Витамин К — 1640 мгк
- Витамин А — 421 мгк
Минералы:
- Кальций — 138 мг
- Железо — 6,2 мг
- Магний — 50 мг
- Фосфор — 58 мг
- Калий — 554 мг (16%)
В петрушке есть органические кислоты, флавоноиды, фитонциды, растительные волокна и эфирные масла. А еще тиамин, рибофлавин, ниацин и фолиевая кислота.
А еще тиамин, рибофлавин, ниацин и фолиевая кислота.
Польза петрушки
Полезное воздействие петрушки:
- антиоксидантное,
- болеутоляющее,
- противогрибковое,
- мочегонное,
- антибактериальное и др.
Пищевые волокна и клетчатка в составе петрушки повышают моторику кишечника. Она полезна для укрепления костей, поддержания здоровья глаз и профилактики заболеваний. Вот несколько фактов о пользе петрушки для здоровья:
1. Содержит антиоксиданты
В петрушке много антиоксидантов, известных как флавоноиды. Два основных из них в составе растения: мирицетин и апигенин [2]. Исследования подтверждают роль мирицетина в противодиабетических, противоопухолевых, иммуномодулирующих и кардиозащитных процессах [3].
Апигенин улучшает формирование нейронов и укрепляет связи между клетками мозга. Благодаря этому он помогает концентрации внимания и стимулирует работу памяти. Ряд исследователей рассматривают апигенин как новый инструмент для отсрочки начала болезни Альцгеймера или замедления ее прогрессирования [4].
Ряд исследователей рассматривают апигенин как новый инструмент для отсрочки начала болезни Альцгеймера или замедления ее прогрессирования [4].
2. Укрепляет кости
Витамин К, которым особенно богата петрушка, помогает укрепить кости и увеличивает их минеральную плотность. Снижение последней напрямую связано с риском переломов, особенно у пожилых людей. Употребление продуктов с высоким содержанием витамина К уменьшает эту возможность [5]. Одно из исследований показало, что в контрольной группе с высоким потреблением витамина К число переломов костей регистрировалось на 22% меньше [6]. Петрушка также содержит кальций, эргостерин и витамин С, которые в совокупности помогают сохранить кости крепкими [7].
3. Улучшает зрение
Три каротиноида в составе петрушки — лютеин, бета-каротин и зеаксантин — помогают сохранять зрение и поддерживать здоровье глаз. Существуют исследования, доказывающие, что высокое потребление каротиноидов с пищей, в частности лютеина и зеаксантина, снижает возрастную дегенерацию желтого пятна (АMD) [8]. Бета-каротин метаболизируется в организме в витамин А (или ретинол), который в частности защищает роговицу и конъюнктиву глаз. Он также улучшает ночное и периферическое зрение [9].
Бета-каротин метаболизируется в организме в витамин А (или ретинол), который в частности защищает роговицу и конъюнктиву глаз. Он также улучшает ночное и периферическое зрение [9].
4. Поддерживает работу сердца
Все те же флавоноиды снижают окислительный стресс и тем самым укрепляют здоровье сердечно-сосудистой системы. Питательные вещества петрушки помогают снизить кровяное давление и уровень холестерина, укрепить стенки сосудов.
Исследование с участием более чем 58 000 человек показало, что у группы с максимальным потреблением фолиевой кислоты риск развития сердечных заболеваний был снижен на 38% [10].
5. Борется с микробами
В виде экстракта петрушка обладает антибактериальными и противогрибковыми свойствами. Ряд исследований (в пробирке) показали, что в таком виде петрушка показывала активность против бактерий Staphylococcus aureus, которые могут вызывать пневмонию и менингит. Экстракт петрушки также помогает предотвратить рост бактерий в пище, например Listeria и Salmonella, которые вызывают острое отравление [11].
«Особое внимание в составе петрушки стоит обратить на эвгенол — эфирное масло с выраженным противовоспалительным эффектом. Он позволяет укреплять иммунитет и повысить стойкость к вирусным заболеваниям, что особенно актуально в осенне-зимний период», — комментирует Александра Разаренова.
6. Помогает работе почек
Петрушка способствует учащению мочеиспускания, уменьшению выведения кальция и повышению кислотности мочи для лечения камней в почках. Однако исследования этого вопроса на людях пока ограниченны. Но опыты с крысами показали, что группа животных, которым давали экстракт семян петрушки, выводили больший объем мочи за сутки [12].
Применение петрушки петрушки в кулинарии
© Karolina Grabowska/Pixabay
Петрушка сочетается со всеми группами продуктов, как с растительными, так и животными белками. Идеальные партнеры по тарелке для петрушки — укроп, зеленый лук, базилик. В зимний период будет идеально сочетаться с ферментированными продуктами, например с квашеной капустой, советует нутрициолог Разаренова.
Идеальные партнеры по тарелке для петрушки — укроп, зеленый лук, базилик. В зимний период будет идеально сочетаться с ферментированными продуктами, например с квашеной капустой, советует нутрициолог Разаренова.
По словам эксперта, в паре с сельдереем петрушка укрепляет потенцию и увеличивает ее продолжительность.
«Для терапевтических эффектов достаточно употребления 50 г петрушки ежедневно. Но если к этому нет противопоказаний», — говорит врач.
Применение петрушки в косметологии
Еще одно применение петрушки — маски и лосьоны для улучшения кожи лица. Все средства можно разделить на две группы: первые — это домашние маски, которые делаются из листьев растения; вторые основаны на эфирном масле, источником которого служат корни, листья и семена петрушки.
Считается, что такие средства убирают пигментацию кожи, защищают ее от УФ-лучей, снимают раздражение и покраснения, а также оказывают общеукрепляющий эффект.
Однако дерматологи предупреждают, что возможности фитопрепаратов очень ограниченны.
«Можно добиться легкого косметического эффекта, который будет несопоставим с современными средствами ухода», — говорит дерматолог Юлия Галлямова.
«Наружное применение средств из петрушки (отвары, эфирные масла) позволяет снизить пигментацию кожи, осветлить отдельные пятна и увлажнить кожу. Также не стоит питать иллюзию, что эфирные масла трав и в частности петрушки безопасны для кожи. На них может развиться аллергическая реакция в виде покраснения, шелушения и зуда. В таком случае необходимо отказаться от применения этих средств», — предупреждает Юлия.
Противопоказания
Петрушка официально признана безопасным растением [13]. Возможные побочные реакции связаны с аллергией. Особенно если есть непереносимость других членов семейства зонтичных: моркови, сельдерея и фенхеля.
По словам Александры Разореновой, есть петрушку, особенно в больших объемах, следует с осторожностью при следующих состояниях:
- гипертония
- гипотиреоз
- подагра
- мочекаменная болезнь
- ранние сроки беременности
- заболевания печени, почек
- при приеме препаратов, разжижающих кровь.

разделить-применить-объединить — документация pandas 1.3.5
Под «группировкой» мы подразумеваем процесс, включающий одно или несколько из следующих действий. шагов:
Разделение данных на группы на основе некоторых критериев.
Применение функции к каждой группе независимо.
Объединение результатов в структуру данных.
Из них шаг разделения является самым простым.На самом деле во многих ситуациях мы можем захотеть разделить набор данных на группы и сделать что-то с те группы. На этапе применения мы можем захотеть выполнить одно из далее:
Агрегирование : вычислить сводную статистику (или статистику) для каждого группа. Некоторые примеры:
Преобразование : выполнить некоторые групповые вычисления и вернуть объект с подобным индексом.
Некоторые примеры:Фильтрация : отбросить некоторые группы в соответствии с групповым вычислением который оценивает True или False.Некоторые примеры:
Некоторая комбинация вышеперечисленного: GroupBy проверит результаты применения шаг и попытаться вернуть разумно объединенный результат, если он не вписывается в любой из двух вышеуказанных категорий.
 Некоторые примеры:
Некоторые примеры: Поскольку набор методов экземпляра объекта в структурах данных pandas обычно
богатый и выразительный, мы часто просто хотим вызвать, скажем, функцию DataFrame
на каждой группе. Имя GroupBy должно быть хорошо знакомо тем, кто использовал
инструмент на основе SQL (или itertools ), в котором вы можете написать код вроде:
ВЫБЕРИТЕ Столбец1, Столбец2, среднее (Столбец3), сумма (Столбец4) ОТ SomeTable СГРУППИРОВАТЬ ПО столбцу1, столбцу2
Мы стремимся сделать подобные операции естественными и простыми для выражения с помощью
панды. Мы рассмотрим каждую область функциональности GroupBy, а затем предоставим некоторые
нетривиальные примеры/использования.
Мы рассмотрим каждую область функциональности GroupBy, а затем предоставим некоторые
нетривиальные примеры/использования.
См. кулинарную книгу для некоторых продвинутых стратегий.
Разделение объекта на группы
объекта панд можно разделить по любой из их осей. Абстрактное определение группировка заключается в обеспечении сопоставления меток с именами групп. Чтобы создать GroupBy объект (подробнее о том, что такое объект GroupBy позже), вы можете сделать следующее:
В [1]: df = pd.DataFrame(
...: [
...: ("птица", "Соколиные", 389,0),
...: ("птица", "Попугаеобразные", 24,0),
...: ("млекопитающее", "Плотоядное", 80,2),
...: ("млекопитающее", "Приматы", np.nan),
...: ("Млекопитающее", "Плотоядное", 58),
...: ],
...: index=["сокол", "попугай", "лев", "обезьяна", "леопард"],
...: columns=("класс", "порядок", "max_speed"),
...:)
...:
В [2]: дф
Выход[2]:
порядок класса max_speed
сокол птица Falconiformes 389.0
попугай птица Psittaciformes 24. 0
лев млекопитающее Carnivora 80,2
обезьяна млекопитающее приматы NaN
леопардовое млекопитающее Carnivora 58,0
# по умолчанию ось=0
В [3]: grouped = df.groupby("класс")
В [4]: grouped = df.groupby("order", axis="columns")
В [5]: grouped = df.groupby(["класс", "порядок"])
 0
лев млекопитающее Carnivora 80,2
обезьяна млекопитающее приматы NaN
леопардовое млекопитающее Carnivora 58,0
# по умолчанию ось=0
В [3]: grouped = df.groupby("класс")
В [4]: grouped = df.groupby("order", axis="columns")
В [5]: grouped = df.groupby(["класс", "порядок"])
0
лев млекопитающее Carnivora 80,2
обезьяна млекопитающее приматы NaN
леопардовое млекопитающее Carnivora 58,0
# по умолчанию ось=0
В [3]: grouped = df.groupby("класс")
В [4]: grouped = df.groupby("order", axis="columns")
В [5]: grouped = df.groupby(["класс", "порядок"])
Отображение может быть указано разными способами:
Функция Python, вызываемая для каждой из меток оси.
Список или массив NumPy той же длины, что и выбранная ось.
A dict или
Series, предоставляя метку-> сопоставление имени группы.Для объектов
DataFrameстрока, указывающая либо имя столбца, либо имя уровня индекса, которое будет использоваться для группировки.df.groupby('A')— это просто синтаксический сахар дляdf.groupby(df['A']).Список всего вышеперечисленного.
В совокупности мы называем объекты группировки ключами . Например,
рассмотрим следующие
Например,
рассмотрим следующие DataFrame :
Примечание
Строка, переданная в groupby , может относиться либо к столбцу, либо к уровню индекса.
Если строка совпадает как с именем столбца, так и с именем уровня индекса, Будет выдано значение ValueError .
В [6]: df = pd.DataFrame(
...: {
...: "A": ["foo", "bar", "foo", "bar", "foo", "bar", "foo", "foo"],
...: "В": ["один", "один", "два", "три", "два", "два", "один", "три"],
...: "C": np.random.randn(8),
...: "D": np.random.randn(8),
...: }
...:)
...:
В [7]: дф
Выход[7]:
А Б В Г
0 foo один 0,469112 -0,861849
1 бар один -0,282863 -2,104569
2 фу два -1,509059 -0,494929
3 бар три -1,135632 1,071804
4 фу два 1,212112 0,721555
5 бар два -0,173215 -0,706771
6 foo один 0,119209 -1,039575
7 фу три -1,044236 0,271860
В DataFrame мы получаем объект GroupBy, вызывая groupby() .Естественно, мы могли бы сгруппировать либо по столбцам A , либо по столбцам B , либо по обоим столбцам:
В [8]: grouped = df.
 groupby("A")
В [9]: grouped = df.groupby(["A", "B"])
groupby("A")
В [9]: grouped = df.groupby(["A", "B"])
Если у нас также есть MultiIndex для столбцов A и B , мы можем сгруппировать по всем
но указанные столбцы
В [10]: df2 = df.set_index(["A", "B"])
В [11]: grouped = df2.groupby(level=df2.index.names.difference(["B"]))
В [12]: grouped.sum()
Выход[12]:
КОМПАКТ ДИСК
А
бар -1.591710 -1.739537
фу -0,752861 -1,402938
Они разделят DataFrame на его индекс (строки). Мы могли бы также разделить столбцы:
В [13]: def get_letter_type(letter): ....: если letter.lower() в 'aeiou': ....: вернуть гласную ....: еще: ....: вернуть 'согласный' ....: В [14]: grouped = df.groupby(get_letter_type, axis=1)Объекты
pandas Index поддерживают повторяющиеся значения. Если
неуникальный индекс используется в качестве группового ключа в операции groupby, все значения
для одного и того же значения индекса будет считаться принадлежащим к одной группе, и, таким образом,
вывод функций агрегации будет содержать только уникальные значения индекса:
В [15]: lst = [1, 2, 3, 1, 2, 3] В [16]: s = pd.
 Серии([1, 2, 3, 10, 20, 30], лст)
В [17]: grouped = s.groupby(level=0)
В [18]: grouped.first()
Вышли[18]:
1 1
2 2
3 3
тип: int64
В [19]: grouped.last()
Вышли[19]:
1 10
2 20
3 30
тип: int64
В [20]: grouped.sum()
Исход[20]:
1 11
2 22
3 33
тип: int64
Серии([1, 2, 3, 10, 20, 30], лст)
В [17]: grouped = s.groupby(level=0)
В [18]: grouped.first()
Вышли[18]:
1 1
2 2
3 3
тип: int64
В [19]: grouped.last()
Вышли[19]:
1 10
2 20
3 30
тип: int64
В [20]: grouped.sum()
Исход[20]:
1 11
2 22
3 33
тип: int64
Обратите внимание, что разбиение не происходит до тех пор, пока оно не понадобится. Создание объекта GroupBy только проверяет, что вы передали действительное сопоставление.
Примечание
Многие виды сложных операций с данными могут быть выражены в терминах Операции GroupBy (хотя нельзя гарантировать, что они будут самыми эффективный).Вы можете проявить творческий подход к функциям сопоставления меток.
Групповая сортировка
По умолчанию групповые ключи сортируются во время операции groupby . Однако вы можете передать sort=False для потенциального ускорения:
В [21]: df2 = pd.DataFrame({"X": ["B", "B", "A", "A"], "Y": [1, 2, 3, 4]})
В [22]: df2. groupby(["X"]).sum()
Вышли[22]:
Д
Икс
А 7
Б 3
В [23]: df2.groupby(["X"], sort=False).sum()
Вышли[23]:
Д
Икс
Б 3
А 7
 groupby(["X"]).sum()
Вышли[22]:
Д
Икс
А 7
Б 3
В [23]: df2.groupby(["X"], sort=False).sum()
Вышли[23]:
Д
Икс
Б 3
А 7
groupby(["X"]).sum()
Вышли[22]:
Д
Икс
А 7
Б 3
В [23]: df2.groupby(["X"], sort=False).sum()
Вышли[23]:
Д
Икс
Б 3
А 7
Обратите внимание, что groupby сохранит порядок, в котором наблюдений сортируются внутри каждой группы.Например, группы, созданные groupby() ниже, расположены в том порядке, в котором они появились в исходном DataFrame :
В [24]: df3 = pd.DataFrame({"X": ["A", "B", "A", "B"], "Y": [1, 4, 3, 2]})
В [25]: df3.groupby(["X"]).get_group("A")
Вышли[25]:
Х Г
0 А 1
2 А 3
В [26]: df3.groupby(["X"]).get_group("B")
Вышли[26]:
Х Г
1 Б 4
3 Б 2
ГруппаОт dropna
По умолчанию NA Значения исключаются из групповых ключей во время операции groupby .Тем не мение,
если вы хотите включить значений NA в групповые ключи, вы можете передать dropna=False для этого.
В [27]: df_list = [[1, 2, 3], [1, Нет, 4], [2, 1, 3], [1, 2, 2]] В [28]: df_dropna = pd.
 DataFrame(df_list, columns=["a", "b", "c"])
В [29]: df_dropna
Вышли[29]:
а б в
0 1 2,0 3
1 1 NaN 4
2 2 1,0 3
3 1 2,0 2
DataFrame(df_list, columns=["a", "b", "c"])
В [29]: df_dropna
Вышли[29]:
а б в
0 1 2,0 3
1 1 NaN 4
2 2 1,0 3
3 1 2,0 2
# По умолчанию для ``dropna`` установлено значение True, что исключает NaN в ключах
В [30]: df_dropna.groupby(by=["b"], dropna=True).сумма()
Исход[30]:
а с
б
1,0 2 3
2,0 2 5
# Чтобы разрешить NaN в ключах, установите ``dropna`` в False
В [31]: df_dropna.groupby(by=["b"], dropna=False).sum()
Вышел[31]:
а с
б
1,0 2 3
2,0 2 5
NaN 1 4
Значение по умолчанию аргумента dropna равно True , что означает, что NA не включены в групповые ключи.
Атрибуты объекта GroupBy
Атрибут groups представляет собой словарь, ключи которого являются вычисленными уникальными группами
и соответствующие значения являются метками осей, принадлежащими каждой группе.в
выше пример у нас есть:
В [32]: df.groupby("A").groups
Out[32]: {'bar': [1, 3, 5], 'foo': [0, 2, 4, 6, 7]}
В [33]: df. groupby(get_letter_type, axis=1).groups
Out[33]: {'согласная': ['B', 'C', 'D'], 'гласная': ['A']}
 groupby(get_letter_type, axis=1).groups
Out[33]: {'согласная': ['B', 'C', 'D'], 'гласная': ['A']}
groupby(get_letter_type, axis=1).groups
Out[33]: {'согласная': ['B', 'C', 'D'], 'гласная': ['A']}
Вызов стандартной функции Python len для объекта GroupBy просто возвращает результат
длина групп dict, так что это в основном просто удобство:
В [34]: grouped = df.groupby(["A", "B"])
В [35]: grouped.groups
Out[35]: {('штрих', 'один'): [1], ('штрих', 'три'): [3], ('штрих', 'два'): [5], (' foo', 'один'): [0, 6], ('foo', 'три'): [7], ('foo', 'два'): [2, 4]}
В [36]: len(сгруппировано)
Аут[36]: 6
GroupBy будет отображать полные имена столбцов (и другие атрибуты):
В [37]: df
Вышли[37]:
рост вес пол
2000-01-01 42.849980 157.500553 мужской
02.01.2000 49.607315 177.340407 мужчина
03.01.2000 56.293531 171.524640 мужчина
04.01.2000 48.421077 144.251986 жен.
05.01.2000 46.556882 152.526206 мужчина
06.01.2000 68.448851 168.272968 женщина
07.01.2000 70.757698 136.431469 мужчина
08.01.2000 58. 0 176.499753 жен.
09.01.2000 76.435631 174.094104 жен.
2000-01-10 45.306120 177.540920 мужчина
В [38]: gb = df.groupby("пол")

В [39]: gb.# noqa: E225, E999 гб.agg gb.boxplot gb.cummin gb.describe gb.filter gb.get_group gb.height gb.last gb.median gb.ngroups gb.plot gb.rank gb.std gb.transform gb.aggregate gb.count gb.cumprod gb.dtype gb.first gb.groups gb.hist gb.max gb.min gb.nth gb.prod gb.resample gb.sum gb.var gb.apply gb.cummax gb.cumsum gb.fillna gb.gender gb.head gb.indices gb.mean gb.name gb.ohlc gb.quantile gb.size gb.tail gb.weight
GroupBy с мультииндексом
С иерархически индексированными данными вполне естественно сгруппировать по одному из уровней иерархии.
Создадим Series с двухуровневым MultiIndex .
В [40]: массивы = [ ....: ["бар", "бар", "баз", "баз", "фу", "фу", "кукс", "кукс"], ....: ["один", "два", "один", "два", "один", "два", "один", "два"], ....: ] ....: В [41]: index = pd.два 0,495767 квкс один 0.362949 два 1.548106 тип: float64
 MultiIndex.from_arrays (массивы, имена = ["первый", "второй"])
В [42]: s = pd.Series(np.random.randn(8), index=index)
В [43]: с
Вышел[43]:
первая секунда
бар один -0,919854
два -0,042379
баз один 1.247642
два -0,009920
фу один 0.2
MultiIndex.from_arrays (массивы, имена = ["первый", "второй"])
В [42]: s = pd.Series(np.random.randn(8), index=index)
В [43]: с
Вышел[43]:
первая секунда
бар один -0,919854
два -0,042379
баз один 1.247642
два -0,009920
фу один 0.2 Затем мы можем сгруппировать по одному из уровней s .
В [44]: grouped = s.groupby(level=0) В [45]: сгруппировано.сумма() Вышли[45]: первый бар -0,962232 баз 1.237723 фу 0.785980 квкс 1.5 тип: float64
Если для MultiIndex указаны имена, их можно передать вместо уровня номер:
В [46]: s.groupby(level="second").sum() Вышел[46]: второй один 0,980950 два 1.991575 тип: float64
Поддерживается многоуровневая группировка.
В [47]: с
Вышел[47]:
первый второй третий
бар доо один -1.131345
два -0,089329
баз би один 0.337863
два -0,945867
фу боп один -0.932132
два 1. 956030
qux боп один 0,017587
два -0,016692
тип: float64
В [48]: s.groupby(level=["first", "second"]).sum()
Вышел[48]:
первая секунда
бар доо -1.220674
баз пчелиный -0,608004
фу боп 1.023898
Qux боп 0.000895
тип: float64
 956030
qux боп один 0,017587
два -0,016692
тип: float64
В [48]: s.groupby(level=["first", "second"]).sum()
Вышел[48]:
первая секунда
бар доо -1.220674
баз пчелиный -0,608004
фу боп 1.023898
Qux боп 0.000895
тип: float64
956030
qux боп один 0,017587
два -0,016692
тип: float64
В [48]: s.groupby(level=["first", "second"]).sum()
Вышел[48]:
первая секунда
бар доо -1.220674
баз пчелиный -0,608004
фу боп 1.023898
Qux боп 0.000895
тип: float64
Имена индексных уровней могут быть предоставлены в виде ключей.
В [49]: s.groupby(["first", "second"]).sum() Вышел[49]: первая секунда бар доо -1.220674 баз пчелиный -0,608004 фу боп 1.023898 Qux боп 0.000895 тип: float64
Подробнее о функции sum и агрегации позже.
Группировка DataFrame с уровнями индекса и столбцами
DataFrame может быть сгруппирован по комбинации столбцов и уровней индекса
указание имен столбцов в виде строк и уровней индекса в виде pd.Grouper объекты.
В [50]: массивы = [ ....: ["бар", "бар", "баз", "баз", "фу", "фу", "кукс", "кукс"], ....: ["один", "два", "один", "два", "один", "два", "один", "два"], ....: ] ....: В [51]: index = pd.
 MultiIndex.from_arrays(массивы, имена=["первый", "второй"])
В [52]: df = pd.DataFrame({"A": [1, 1, 1, 1, 2, 2, 3, 3], "B": np.arange(8)}, index=index)
В [53]: дф
Вышел[53]:
А Б
первая секунда
бар один 1 0
два 1 1
баз один 1 2
два 1 3
фу один 2 4
два 2 5
один 3 6
два 3 7
MultiIndex.from_arrays(массивы, имена=["первый", "второй"])
В [52]: df = pd.DataFrame({"A": [1, 1, 1, 1, 2, 2, 3, 3], "B": np.arange(8)}, index=index)
В [53]: дф
Вышел[53]:
А Б
первая секунда
бар один 1 0
два 1 1
баз один 1 2
два 1 3
фу один 2 4
два 2 5
один 3 6
два 3 7
В следующем примере df группируются по второму уровню индекса и
колонка А .
В [54]: df.groupby([pd.Grouper(level=1), "A"]).sum()
Вышел[54]:
Б
второй А
один 1 2
2 4
3 6
два 1 4
2 5
3 7
Уровни индекса также могут быть указаны по имени.
В [55]: df.groupby([pd.Grouper(level="second"), "A"]).sum()
Вышел[55]:
Б
второй А
один 1 2
2 4
3 6
два 1 4
2 5
3 7
Имена уровней индексов могут быть указаны как ключи непосредственно для groupby .
В [56]: df.groupby(["second", "A"]).sum()
Вышел[56]:
Б
второй А
один 1 2
2 4
3 6
два 1 4
2 5
3 7
Выбор столбца DataFrame в GroupBy
После того, как вы создали объект GroupBy из DataFrame, вы можете захотеть сделать
что-то другое для каждой из колонок. Таким образом, используя
Таким образом, используя [] аналогично
получить столбец из DataFrame, вы можете сделать:
В [57]: grouped = df.groupby(["A"]) В [58]: grouped_C = grouped["C"] В [59]: grouped_D = grouped["D"]
Это в основном синтаксический сахар для альтернативы и гораздо более подробный:
В [60]: df["C"].групповой (df ["A"]) Out[60]: <объект pandas.core.groupby.generic.SeriesGroupBy по адресу 0x7f064886cdc0>
Кроме того, этот метод позволяет избежать повторного вычисления внутренней информации о группировке. полученный из переданного ключа.
Перебор групп
При наличии объекта GroupBy повторение сгруппированных данных очень
естественный и работает аналогично itertools.groupby() :
В [61]: grouped = df.groupby('A')
В [62]: для имени, группа в группе:
....: печать (имя)
....: печать (группа)
....:
бар
А Б В Г
1 бар один 0,254161 1,511763
3 бар три 0,215897 -0,9
5 бар два -0,077118 1,211526
фу
А Б В Г
0 foo один -0,575247 1,346061
2 foo два -1,143704 1,627081
4 фу два 1,193555 -0,441652
6 foo один -0,408530 0,268520
7 foo три -0,862495 0,024580
В случае группировки по нескольким ключам имя группы будет кортежем:
В [63]: для имени, группы в df.(«бар», «два») А Б В Г 5 бар два -0,077118 1,211526 («фу», «один») А Б В Г 0 foo один -0,575247 1,346061 6 foo один -0,408530 0,268520 («фу», «три») А Б В Г 7 фу три -0.862495 0,02458 («фу», «два») А Б В Г 2 foo два -1,143704 1,627081 4 фу два 1,193555 -0,441652
 группа(['А', 'Б']):
....: печать (имя)
....: печать (группа)
....:
(«бар», «один»)
А Б В Г
1 бар один 0,254161 1,511763
(«бар», «три»)
А Б В Г
3 бар три 0,215897 -0,9
группа(['А', 'Б']):
....: печать (имя)
....: печать (группа)
....:
(«бар», «один»)
А Б В Г
1 бар один 0,254161 1,511763
(«бар», «три»)
А Б В Г
3 бар три 0,215897 -0,9См. Перебор групп.
Выбор группы
Одну группу можно выбрать с помощью get_group() :
В [64]: grouped.get_group("bar")
Вышел[64]:
А Б В Г
1 бар один 0,254161 1,511763
3 бар три 0,215897 -0,9
5 бар два -0,077118 1,211526
Или для объекта, сгруппированного по нескольким столбцам:
В [65]: df.groupby(["A", "B"]).get_group(("bar", "one"))
Вышел[65]:
А Б В Г
1 бар один 0,254161 1,511763
Агрегация
После создания объекта GroupBy доступны несколько методов для
выполнить вычисление по сгруппированным данным. Эти операции аналогичны
агрегирующий API, оконный API,
и пересэмплировать API.
Эти операции аналогичны
агрегирующий API, оконный API,
и пересэмплировать API.
Очевидным является агрегирование через агрегат() или аналогичный agg() метод:
В [66]: grouped = df.сгруппировать("А")
В [67]: grouped.aggregate(np.sum)
Вышел[67]:
КОМПАКТ ДИСК
А
бар 0,392940 1,732707
фу -1,796421 2,824590
В [68]: grouped = df.groupby(["A", "B"])
В [69]: grouped.aggregate(np.sum)
Вышел[69]:
КОМПАКТ ДИСК
А Б
бар один 0,254161 1,511763
три 0,215897 -0,9
два -0,077118 1,211526
фу один -0,983776 1,614581
три -0,862495 0,024580
два 0,049851 1,185429
Как видите, результат агрегации будет иметь имена групп в качестве
новый индекс вдоль сгруппированной оси.В случае нескольких ключей результатом будет
MultiIndex по умолчанию, хотя это может быть
изменено с помощью опции as_index :
В [70]: grouped = df.groupby(["A", "B"], as_index=False) В [71]: grouped.aggregate(np.2 бар два -0,077118 1,211526 3 foo один -0,983776 1,614581 4 foo три -0,862495 0,024580 5 foo два 0,049851 1,185429 В [72]: ф.р.groupby("A", as_index=False).sum() Вышел[72]: А В Г 0 бар 0,392940 1,732707 1 фу -1,796421 2,824590
 sum)
Вышел[71]:
А Б В Г
0 бар один 0,254161 1,511763
1 бар три 0,215897 -0,9
sum)
Вышел[71]:
А Б В Г
0 бар один 0,254161 1,511763
1 бар три 0,215897 -0,9 Обратите внимание, что вы можете использовать функцию reset_index DataFrame для достижения
тот же результат, что и имена столбцов, сохраненные в результате MultiIndex :
В [73]: df.groupby(["A", "B"]).sum().reset_index()
Вышел[73]:
А Б В Г
0 бар один 0,254161 1,511763
1 бар три 0,215897 -0,9
2 бар два -0.077118 1.211526
3 foo один -0,983776 1,614581
4 foo три -0,862495 0,024580
5 foo два 0,049851 1,185429
Другой простой пример агрегирования — вычисление размера каждой группы.
Это включено в GroupBy как метод размера . Он возвращает серию, чья
index — это имена групп, значения которых — размеры каждой группы.
В [74]: grouped.size()
Вышел[74]:
Размер А Б
0 бар один 1
1 бар три 1
2 бар два 1
3 фу один 2
4 фу три 1
5 фу два 2
В [75]: сгруппировано.описывать()
Вышел[75]:
КОМПАКТ ДИСК
подсчет среднее стандартное мин. 25% 50% 75% ... среднее стандартное мин. 25% 50% 75% макс.
0 1,0 0,254161 NaN 0,254161 0,254161 0,254161 0,254161 ... 1,511763 NaN 1,511763 1,511763 1,511763 1,511763 1,511763
1 1,0 0,215897 NaN 0,215897 0,215897 0.215897 0,215897 ... -0,9 NaN -0,9
-0,9 -0,9
-0,9 -0,9
2 1,0 -0,077118 NaN -0,077118 -0,077118 -0,077118 -0,077118 ... 1,211526 NaN 1,211526 1,211526 1,211526 1,211526 1,211526
3 2,0 -0,491888 0,117887 -0,575247 -0,533567 -0,491888 -0,450209 ... 0,807291 0,761937 0,268520 0,537905 0,807291 1,076676 1,346061
4 1,0 -0,862495 NaN -0,862495 -0,862495 -0,862495 -0,862495 ... 0,024580 NaN 0,024580 0,024580 0,024580 0.024580 0,024580
5 2,0 0,024925 1,652692 -1,143704 -0,559389 0,024925 0,609240 ... 0,592714 1,462816 -0,441652 0,075531 0,592714 1,109898 1,627081
[6 строк х 16 столбцов]
Другой пример агрегирования — вычисление количества уникальных значений каждой группы. Это похоже на функцию
Это похоже на функцию value_counts , за исключением того, что она подсчитывает только уникальные значения.
В [76]: ll = [['foo', 1], ['foo', 2], ['foo', 2], ['bar', 1], ['bar', 1]]
В [77]: df4 = pd.DataFrame(ll, columns=["A", "B"])
В [78]: df4
Вышел[78]:
А Б
0 фу 1
1 фу 2
2 фу 2
3 бар 1
4 бар 1
В [79]: df4.groupby ("A") ["B"]. nunique ()
Вышел[79]:
А
бар 1
фу 2
Имя: B, dtype: int64
Примечание
Функции агрегации не будут возвращать группы, по которым вы агрегируете
если они названы столбцов , когда as_index=True , по умолчанию. Сгруппированные столбцы будут
быть индексами возвращаемого объекта.
Передача as_index=False вернет группы, по которым вы агрегируете, если они
назвал столбцов .
Агрегирующие функции уменьшают размерность возвращаемых объектов. Некоторые общие функции агрегирования представлены в таблице ниже:
Функция | Описание |
|---|---|
| Вычислить среднее значение групп |
| Вычислить сумму групповых значений |
| Размеры вычислительных групп |
| Вычислить счетчик группы |
| Стандартное отклонение групп |
| Вычислить дисперсию групп |
| Стандартная ошибка среднего по группам |
| Создает описательную статистику |
| Вычислить первое из значений группы |
| Вычислить последнее значение группы |
| Принять n-е значение или подмножество, если n — список |
| Вычисление минимума групповых значений |
| Вычислить максимальное значение группы |
Приведенные выше функции агрегирования исключают значения NA. Любая функция, которая
уменьшает серию
Любая функция, которая
уменьшает серию до скалярного значения, является функцией агрегирования и будет работать,
тривиальный пример: df.groupby('A').agg(lambda ser: 1) . Обратите внимание, что nth() может действовать как редуктор или a
фильтр, см. здесь.
Одновременное применение нескольких функций
С помощью сгруппированных серий вы также можете передать список или список функций для выполнения
агрегация с выводом DataFrame:
В [80]: grouped = df.groupby("A")
В [81]: сгруппировано["C"].agg([np.sum, np.mean, np.std])
Вышел[81]:
сумма среднее стандартное
А
бар 0,392940 0,130980 0,181231
фу -1,796421 -0,359284 0,5
В сгруппированном DataFrame вы можете передать список функций для применения к каждому
столбец, который дает агрегированный результат с иерархическим индексом:
В [82]: grouped.agg([np.sum, np.mean, np.std])
Вышел[82]:
КОМПАКТ ДИСК
Сумма среднее стандартное Сумма среднее стандартное
А
бар 0. 392940 0,130980 0,181231 1,732707 0,577569 1,366330
foo -1,796421 -0,359284 0,5 2,824590 0,564918 0,884785
 392940 0,130980 0,181231 1,732707 0,577569 1,366330
foo -1,796421 -0,359284 0,
392940 0,130980 0,181231 1,732707 0,577569 1,366330
foo -1,796421 -0,359284 0, Полученные агрегаты названы в честь самих функций. если ты
нужно переименовать, тогда вы можете добавить цепочку операций для серии следующим образом:
В [83]: (
....: сгруппировано["C"]
....: .agg([np.sum, np.mean, np.std])
....: .rename(columns={"sum": "foo", "mean": "bar", "std": "baz"})
.... :)
....:
Вышел[83]:
фу бар баз
А
бар 0.392940 0,130980 0,181231
фу -1,796421 -0,359284 0,5
Для сгруппированного DataFrame вы можете переименовать аналогичным образом:
В [84]: (
....: grouped.agg([np.sum, np.mean, np.std]).rename(
....: columns={"sum": "foo", "mean": "bar", "std": "baz"}
.... :)
.... :)
....:
Вышел[84]:
КОМПАКТ ДИСК
фу бар баз фу бар баз
А
бар 0.392940 0,130980 0,181231 1,732707 0,577569 1,366330
foo -1,796421 -0,359284 0,5 2,824590 0,564918 0,884785
Примечание
В общем случае имена выходных столбцов должны быть уникальными. Вы не можете подать заявку
одну и ту же функцию (или две функции с одинаковым именем) к одному и тому же
столбец.
Вы не можете подать заявку
одну и ту же функцию (или две функции с одинаковым именем) к одному и тому же
столбец.
В [85]: grouped["C"].agg(["sum", "sum"])
Вышел[85]:
сумма сумма
А
бар 0,392940 0,392940
фу -1,796421 -1,796421
pandas позволяет предоставлять несколько лямбда-выражений.В данном случае панды
исказит имя (безымянной) лямбда-функции, добавив _ каждой последующей лямбде.
В [86]: grouped["C"].agg([лямбда x: x.max() - x.min(), лямбда x: x.median() - x.mean()])
Вышел[86]:
<лямбда_0> <лямбда_1>
А
бар 0,331279 0,084917
фу 2.337259 -0.215962
Именованное объединение
Для поддержки агрегации по столбцам с контролем над именами выходных столбцов , pandas
принимает специальный синтаксис в GroupBy.agg() , известная как «именованная агрегация», где
Ключевыми словами являются выходные имена столбцов
Значения представляют собой кортежи, первым элементом которых является столбец для выбора а второй элемент — это агрегация, применяемая к этому столбцу.
панды
предоставляет pandas.NamedAggnamedtuple с полями['column', 'aggfunc']чтобы было понятнее аргументы. Как обычно, агрегация может быть вызываемым или строковым псевдонимом.
 панды
предоставляет
панды
предоставляет В [87]: животные = pd.DataFrame(
....: {
....: "вид": ["кошка", "собака", "кошка", "собака"],
....: "высота": [9.1, 6.0, 9.5, 34.0],
....: "вес": [7,9, 7,5, 9,9, 198,0],
....: }
.... :)
....:
В [88]: животные
Вышел[88]:
добрый рост вес
0 кат 9.1 7.9
1 собака 6,0 7,5
2 кат 9,5 9,9
3 собаки 34,0 198,0
В [89]: animals.groupby("kind").agg(
....: min_height=pd.NamedAgg(column="height", aggfunc="min"),
....: max_height=pd.NamedAgg(column="height", aggfunc="max"),
....: средний_вес = pd.NamedAgg (столбец = «вес», aggfunc = np.mean),
.... :)
....:
Вышел[89]:
min_height max_height средний_вес
своего рода
кошка 9,1 9,5 8,90
собака 6,0 34,0 102,75
pandas.NamedAgg — это всего лишь namedtuple . Также разрешены простые кортежи.
Также разрешены простые кортежи.
В [90]: animals.groupby("kind").агг(
....: min_height=("высота", "мин"),
....: max_height=("высота", "макс"),
....: средний_вес = ("вес", np.mean),
.... :)
....:
Вышли[90]:
min_height max_height средний_вес
своего рода
кошка 9,1 9,5 8,90
собака 6,0 34,0 102,75
Если желаемые имена выходных столбцов не являются допустимыми ключевыми словами Python, создайте словарь и распакуйте аргументы ключевого слова
В [91]: животные.groupby("вид").agg(
....: **{
....: "общий вес": pd.NamedAgg(столбец="вес", aggfunc=сумма)
....: }
.... :)
....:
Вышел[91]:
общий вес
своего рода
кот 17.8
собака 205.5
Дополнительные аргументы ключевого слова не передаются функциям агрегации. Только пары
из (столбец, aggfunc) следует передавать как **kwargs . Если ваши функции агрегации
требует дополнительных аргументов, частично примените их с помощью functools. . частичное()
частичное()
Примечание
Для Python 3.5 и более ранних версий порядок **kwargs в функциях не
сохранен. Это означает, что порядок выходных столбцов не будет
последовательный. Чтобы обеспечить последовательный порядок, ключи (и, следовательно, выходные столбцы)
всегда будет сортироваться для Python 3.5.
Именованная агрегация также действительна для агрегаций групп по сериям. В этом случае есть нет выбора столбца, поэтому значения - это просто функции.
В [92]: животные.groupby("вид").height.agg(
....: min_height="мин",
....: max_height="макс",
.... :)
....:
Вышел[92]:
минимальная_высота максимальная_высота
своего рода
кошка 9,1 9,5
собака 6,0 34,0
Применение различных функций к столбцам DataFrame
Передав словарь агрегату , вы можете применить другую агрегацию к
столбцы DataFrame:
В [93]: grouped.agg({"C": np.sum, "D": lambda x: np.std(x, ddof=1)})
Вышел[93]:
КОМПАКТ ДИСК
А
бар 0. 392940 1.366330
фу -1,796421 0,884785
 392940 1.366330
фу -1,796421 0,884785
392940 1.366330
фу -1,796421 0,884785
Имена функций также могут быть строками. Чтобы строка была действительной, должен быть либо реализован на GroupBy, либо доступен через диспетчеризацию:
В [94]: grouped.agg({"C": "sum", "D": "std"})
Вышел[94]:
КОМПАКТ ДИСК
А
бар 0,392940 1,366330
фу -1,796421 0,884785
Функции агрегации, оптимизированные для Cython
Некоторые распространенные агрегации, в настоящее время только sum , mean , std и sem , имеют
оптимизированные реализации Cython:
В [95]: прим.groupby("A").сумма()
Вышел[95]:
КОМПАКТ ДИСК
А
бар 0,392940 1,732707
фу -1,796421 2,824590
В [96]: df.groupby(["A", "B"]).mean()
Вышел[96]:
КОМПАКТ ДИСК
А Б
бар один 0,254161 1,511763
три 0,215897 -0,9
два -0,077118 1,211526
фу один -0,491888 0,807291
три -0,862495 0,024580
два 0,024925 0,592714
Конечно, сумма и означают, что реализованы на объектах pandas, поэтому приведенное выше
код будет работать даже без специальных версий через диспетчеризацию (см. ниже).
ниже).
Агрегации с пользовательскими функциями
Пользователи также могут предоставлять свои собственные функции для пользовательских агрегаций. При объединении
с определяемой пользователем функцией (UDF), UDF не должна изменять предоставленную серию , см.
Мутация с помощью методов определяемой пользователем функции (UDF) для получения дополнительной информации.
В [97]: animals.groupby("kind")[["height"]].agg(lambda x: set(x))
Вышел[97]:
высота
своего рода
кошка {9.1, 9.5}
собака {34,0, 6,0}
Результирующий dtype будет отражать тип агрегатной функции.Если результаты разных групп
разные dtypes, то общий dtype будет определяться так же, как построение DataFrame .
В [98]: animals.groupby("kind")[["height"]].agg(lambda x: x.astype(int).sum())
Вышел[98]:
высота
своего рода
кошка 18
собака 40
Трансформация
Метод преобразования возвращает объект с одинаковым индексом (того же размера). как тот, который группируется. Функция преобразования должна:
как тот, который группируется. Функция преобразования должна:
Возвращает результат того же размера, что и фрагмент группы, или транслируемый до размера группового фрагмента (т.г., скаляр,
grouped.transform(лямбда x: x.iloc[-1])).Работать столбец за столбцом в групповом фрагменте. Преобразование применяется к первый групповой фрагмент с помощью chunk.apply.
Не выполнять оперативные операции над фрагментом группы. Групповые фрагменты должны рассматриваться как неизменяемый, а изменения в групповом блоке могут привести к неожиданным результатам. Результаты. Например, при использовании
fillnaвместодолжно бытьFalse. (сгруппировано.преобразование (лямбда x: x.fillna (inplace = False))).(необязательно) работает со всем фрагментом группы. Если это поддерживается, быстрый путь используется, начиная с второго куска .
Подобно агрегатам с пользовательскими функциями, результирующий тип dtype будет отражать тип
функция трансформации. Если результаты из разных групп имеют разные dtypes, то
общий dtype будет определяться так же, как конструкция
Если результаты из разных групп имеют разные dtypes, то
общий dtype будет определяться так же, как конструкция DataFrame .
Предположим, мы хотим стандартизировать данные внутри каждой группы:
В [99]: index = pd.date_range("1/10/1999", периоды=1100)
В [100]: ts = pd.Series(np.random.normal(0.5, 2, 1100), index)
В [101]: ts = ts.rolling(window=100, min_periods=100).mean().dropna()
В [102]: ts.head()
Выход[102]:
08.01.2000 0,779333
09.01.2000 0,778852
10 января 2000 г. 0,786476
11 января 2000 г. 0,782797
12.01.2000 0,798110
Частота: D, тип d: float64
В [103]: ts.tail()
Выход[103]:
2002-09-30 0.660294
01.10.2002 0.631095
02.10.2002 0,673601
03.10.2002 0,709213
04.10.2002 0,719369
Частота: D, тип d: float64
В [104]: преобразовано = ts.groupby(lambda x: x.year).transform(
.....: лямбда x: (x - x.mean()) / x.std()
.....: )
.....:
Мы ожидаем, что теперь результат будет иметь среднее значение 0 и стандартное отклонение 1 в пределах каждой группы, которую мы можем легко проверить:
# Исходные данные В [105]: grouped = ts.
 groupby(лямбда x: x.год)
В [106]: grouped.mean()
Выход[106]:
2000 0.442441
2001 0,526246
2002 0,459365
тип: float64
В [107]: grouped.std()
Выход[107]:
2000 0,131752
2001 0,210945
2002 0,128753
тип: float64
# Преобразованные данные
В [108]: grouped_trans = transform.groupby(lambda x: x.year)
В [109]: grouped_trans.mean()
Выход[109]:
2000 1.193722э-15
2001 1.945476э-15
2002 1.272949э-15
тип: float64
В [110]: grouped_trans.std()
Выход[110]:
2000 1,0
2001 1.0
2002 1.0
тип: float64
groupby(лямбда x: x.год)
В [106]: grouped.mean()
Выход[106]:
2000 0.442441
2001 0,526246
2002 0,459365
тип: float64
В [107]: grouped.std()
Выход[107]:
2000 0,131752
2001 0,210945
2002 0,128753
тип: float64
# Преобразованные данные
В [108]: grouped_trans = transform.groupby(lambda x: x.year)
В [109]: grouped_trans.mean()
Выход[109]:
2000 1.193722э-15
2001 1.945476э-15
2002 1.272949э-15
тип: float64
В [110]: grouped_trans.std()
Выход[110]:
2000 1,0
2001 1.0
2002 1.0
тип: float64
Мы также можем визуально сравнить исходный и преобразованный наборы данных.
В [111]: compare = pd.DataFrame({"Исходный": ts, "Преобразованный": преобразованный})
В [112]: compare.plot()
Выход[112]:
Функции преобразования, которые имеют выходы меньшего размера, транслируются в соответствуют форме входного массива.
В [113]: ts.groupby(лямбда x: x.year).transform(лямбда x: x.max() - x.min()) Выход[113]: 08.01.2000 0,623893 09.01.2000 0,623893 10 января 2000 г.
 0,623893
11 января 2000 г. 0,623893
12 января 2000 г. 0,623893
...
2002-09-30 0,558275
01.10.2002 0,558275
02.10.2002 0,558275
03.10.2002 0,558275
04.10.2002 0,558275
Частота: D, длина: 1001, тип d: float64
0,623893
11 января 2000 г. 0,623893
12 января 2000 г. 0,623893
...
2002-09-30 0,558275
01.10.2002 0,558275
02.10.2002 0,558275
03.10.2002 0,558275
04.10.2002 0,558275
Частота: D, длина: 1001, тип d: float64
В качестве альтернативы можно использовать встроенные методы для получения тех же результатов.
В [114]: max = ts.groupby(lambda x: x.year).transform("max")
В [115]: min = ts.groupby(lambda x: x.year).transform("min")
В [116]: макс - мин
Выход[116]:
08.01.2000 0,623893
09.01.2000 0,623893
10 января 2000 г. 0,623893
2000-01-11 0.623893
12 января 2000 г. 0,623893
...
2002-09-30 0,558275
01.10.2002 0,558275
02.10.2002 0,558275
03.10.2002 0,558275
04.10.2002 0,558275
Частота: D, длина: 1001, тип d: float64
Другим распространенным преобразованием данных является замена отсутствующих данных групповым средним значением.
В [117]: data_df
Выход[117]:
А Б В
0 1,539708 -1,166480 0,533026
1 1,302092 -0,505754 NaN
2 -0,371983 1,104803 -0,651520
3 -1,309622 1,118697 -1. 161657
4 -1,924296 0,396437 0,812436
.. ... ... ...
995 -0,093110 0,683847 -0,774753
996 -0,185043 1,438572 NaN
997 -0,394469 -0,642343 0,011374
998 -1,174126 1,857148 NaN
999 0,234564 0,517098 0,393534
[1000 строк x 3 столбца]
В [118]: countrys = np.array(["US", "UK", "GR", "JP"])
В [119]: ключ = страны[np.random.randint(0, 4, 1000)]
В [120]: grouped = data_df.groupby(key)
# Количество не-NA в каждой группе
В [121]: grouped.count()
Выход[121]:
А Б В
ГР 209 217 189
240 255 217 иенских рупий
Великобритания 216 231 193
США 239 250 217
В [122]: преобразовано = сгруппировано.преобразование (лямбда x: x.fillna (x.mean ()))
 161657
4 -1,924296 0,396437 0,812436
.. ... ... ...
995 -0,093110 0,683847 -0,774753
996 -0,185043 1,438572 NaN
997 -0,394469 -0,642343 0,011374
998 -1,174126 1,857148 NaN
999 0,234564 0,517098 0,393534
[1000 строк x 3 столбца]
В [118]: countrys = np.array(["US", "UK", "GR", "JP"])
В [119]: ключ = страны[np.random.randint(0, 4, 1000)]
В [120]: grouped = data_df.groupby(key)
# Количество не-NA в каждой группе
В [121]: grouped.count()
Выход[121]:
А Б В
ГР 209 217 189
240 255 217 иенских рупий
Великобритания 216 231 193
США 239 250 217
В [122]: преобразовано = сгруппировано.преобразование (лямбда x: x.fillna (x.mean ()))
161657
4 -1,924296 0,396437 0,812436
.. ... ... ...
995 -0,093110 0,683847 -0,774753
996 -0,185043 1,438572 NaN
997 -0,394469 -0,642343 0,011374
998 -1,174126 1,857148 NaN
999 0,234564 0,517098 0,393534
[1000 строк x 3 столбца]
В [118]: countrys = np.array(["US", "UK", "GR", "JP"])
В [119]: ключ = страны[np.random.randint(0, 4, 1000)]
В [120]: grouped = data_df.groupby(key)
# Количество не-NA в каждой группе
В [121]: grouped.count()
Выход[121]:
А Б В
ГР 209 217 189
240 255 217 иенских рупий
Великобритания 216 231 193
США 239 250 217
В [122]: преобразовано = сгруппировано.преобразование (лямбда x: x.fillna (x.mean ()))
Мы можем убедиться, что групповые средние значения не изменились в преобразованных данных. и что преобразованные данные не содержат NA.
В [123]: grouped_trans = transform.groupby(key)
В [124]: grouped.mean() # исходная группа означает
Выход[124]:
А Б В
ГР -0,098371 -0,015420 0,068053
JP 0,069025 0,023100 -0,077324
Великобритания 0,034069 -0,052580 -0,116525
США 0,058664 -0,020399 0,028603
В [125]: grouped_trans. mean() # преобразование не изменило групповые средние
Выход[125]:
А Б В
ГР -0.098371 -0,015420 0,068053
JP 0,069025 0,023100 -0,077324
Великобритания 0,034069 -0,052580 -0,116525
США 0,058664 -0,020399 0,028603
В [126]: grouped.count() # в оригинале отсутствуют некоторые точки данных
Выход[126]:
А Б В
ГР 209 217 189
240 255 217 иенских рупий
Великобритания 216 231 193
США 239 250 217
В [127]: grouped_trans.count() # считает после преобразования
Исход[127]:
А Б В
ГР 228 228 228
267 267 267 японских йенов
Великобритания 247 247 247
США 258 258 258
В [128]: grouped_trans.size() # Проверить, что количество не-NA равно размеру группы
Исход[128]:
ГР 228
267 японских фунтов
Великобритания 247
США 258
тип: int64
 mean() # преобразование не изменило групповые средние
Выход[125]:
А Б В
ГР -0.098371 -0,015420 0,068053
JP 0,069025 0,023100 -0,077324
Великобритания 0,034069 -0,052580 -0,116525
США 0,058664 -0,020399 0,028603
В [126]: grouped.count() # в оригинале отсутствуют некоторые точки данных
Выход[126]:
А Б В
ГР 209 217 189
240 255 217 иенских рупий
Великобритания 216 231 193
США 239 250 217
В [127]: grouped_trans.count() # считает после преобразования
Исход[127]:
А Б В
ГР 228 228 228
267 267 267 японских йенов
Великобритания 247 247 247
США 258 258 258
В [128]: grouped_trans.size() # Проверить, что количество не-NA равно размеру группы
Исход[128]:
ГР 228
267 японских фунтов
Великобритания 247
США 258
тип: int64
mean() # преобразование не изменило групповые средние
Выход[125]:
А Б В
ГР -0.098371 -0,015420 0,068053
JP 0,069025 0,023100 -0,077324
Великобритания 0,034069 -0,052580 -0,116525
США 0,058664 -0,020399 0,028603
В [126]: grouped.count() # в оригинале отсутствуют некоторые точки данных
Выход[126]:
А Б В
ГР 209 217 189
240 255 217 иенских рупий
Великобритания 216 231 193
США 239 250 217
В [127]: grouped_trans.count() # считает после преобразования
Исход[127]:
А Б В
ГР 228 228 228
267 267 267 японских йенов
Великобритания 247 247 247
США 258 258 258
В [128]: grouped_trans.size() # Проверить, что количество не-NA равно размеру группы
Исход[128]:
ГР 228
267 японских фунтов
Великобритания 247
США 258
тип: int64
Примечание
Некоторые функции автоматически преобразуют ввод при применении к
GroupBy, но возвращающий объект той же формы, что и оригинал.Передача as_index=False не повлияет на эти методы преобразования.
Например: fillna, ffill, bfill, shift. .
В [129]: grouped.ffill()
Исход[129]:
А Б В
0 1,539708 -1,166480 0,533026
1 1,302092 -0,505754 0,533026
2 -0,371983 1,104803 -0,651520
3 -1,309622 1,118697 -1,161657
4 -1,924296 0,396437 0,812436
.. ... ... ...
995 -0,093110 0,683847 -0,774753
996 -0,185043 1,438572 -0.774753
997 -0,394469 -0,642343 0,011374
998 -1,174126 1,857148 -0,774753
999 0,234564 0,517098 0,393534
[1000 строк x 3 столбца]
Операции с окном и передискретизацией
Можно использовать resample() , Expanding() и roll() как методы для groupbys.
В приведенном ниже примере метод Rolling() применяется к образцам
столбец B на основе групп столбца A.
В [130]: df_re = pd.DataFrame({"A": [1] * 10 + [5] * 10, "B": np.упорядочить(20)})
В [131]: df_re
Выход[131]:
А Б
0 1 0
1 1 1
2 1 2
3 1 3
4 1 4
.. .. ..
15 5 15
16 5 16
17 5 17
18 5 18
19 5 19
[20 строк х 2 столбца]
В [132]: df_re. groupby("A").rolling(4).B.mean()
Выход[132]:
А
1 0 NaN
1 NaN
2 NaN
3 1,5
4 2,5
...
5 15 13,5
16 14,5
17 15,5
18 16,5
19 17,5
Имя: B, длина: 20, dtype: float64
 groupby("A").rolling(4).B.mean()
Выход[132]:
А
1 0 NaN
1 NaN
2 NaN
3 1,5
4 2,5
...
5 15 13,5
16 14,5
17 15,5
18 16,5
19 17,5
Имя: B, длина: 20, dtype: float64
groupby("A").rolling(4).B.mean()
Выход[132]:
А
1 0 NaN
1 NaN
2 NaN
3 1,5
4 2,5
...
5 15 13,5
16 14,5
17 15,5
18 16,5
19 17,5
Имя: B, длина: 20, dtype: float64
Метод expand() будет накапливать заданную операцию
( sum() в примере) для всех членов каждого конкретного
группа.
В [133]: df_re.groupby("A").expanding().sum()
Исход[133]:
Б
А
1 0 0,0
1 1,0
2 3.0
3 6,0
4 10,0
... ...
5 15 75,0
16 91,0
17 108,0
18 126,0
19 145,0
[20 строк х 1 столбец]
Предположим, вы хотите использовать метод resample() для получения ежедневного
частоту в каждой группе вашего фрейма данных и хотите завершить
пропущенные значения с помощью метода ffill() .
В [134]: df_re = pd.DataFrame(
.....: {
.....: "дата": pd.date_range(start="2016-01-01", периоды=4, freq="W"),
.....: "группа": [1, 1, 2, 2],
.....: "вал": [5, 6, 7, 8],
.....: }
. ....: ).set_index("дата")
.....:
В [135]: df_re
Выход[135]:
групповое значение
Дата
2016-01-03 1 5
2016-01-10 1 6
2016-01-17 2 7
2016-01-24 2 8
В [136]: df_re.groupby("group").resample("1D").ffill()
Исход[136]:
групповое значение
групповое свидание
1 03.01.2016 1 5
2016-01-04 1 5
2016-01-05 1 5
2016-01-06 1 5
2016-01-07 1 5
... ... ...
2 2016-01-20 2 7
2016-01-21 2 7
2016-01-22 2 7
2016-01-23 2 7
2016-01-24 2 8
[16 строк х 2 столбца]
 ....: ).set_index("дата")
.....:
В [135]: df_re
Выход[135]:
групповое значение
Дата
2016-01-03 1 5
2016-01-10 1 6
2016-01-17 2 7
2016-01-24 2 8
В [136]: df_re.groupby("group").resample("1D").ffill()
Исход[136]:
групповое значение
групповое свидание
1 03.01.2016 1 5
2016-01-04 1 5
2016-01-05 1 5
2016-01-06 1 5
2016-01-07 1 5
... ... ...
2 2016-01-20 2 7
2016-01-21 2 7
2016-01-22 2 7
2016-01-23 2 7
2016-01-24 2 8
[16 строк х 2 столбца]
....: ).set_index("дата")
.....:
В [135]: df_re
Выход[135]:
групповое значение
Дата
2016-01-03 1 5
2016-01-10 1 6
2016-01-17 2 7
2016-01-24 2 8
В [136]: df_re.groupby("group").resample("1D").ffill()
Исход[136]:
групповое значение
групповое свидание
1 03.01.2016 1 5
2016-01-04 1 5
2016-01-05 1 5
2016-01-06 1 5
2016-01-07 1 5
... ... ...
2 2016-01-20 2 7
2016-01-21 2 7
2016-01-22 2 7
2016-01-23 2 7
2016-01-24 2 8
[16 строк х 2 столбца]
Фильтрация
Метод filter возвращает подмножество исходного объекта. Предположим, мы
хотите взять только элементы, принадлежащие группам с групповой суммой больше
чем 2.
В [137]: sf = pd.Series([1, 1, 2, 3, 3, 3]) В [138]: sf.groupby(sf).filter(lambda x: x.сумма () > 2) Исход[138]: 3 3 4 3 5 3 тип: int64
Аргумент фильтра должен быть функцией, которая применяется к группе как
в целом, возвращает True или False .
Еще одна полезная операция — фильтрация элементов, принадлежащих группам всего с парой участников.
В [139]: dff = pd.DataFrame({"A": np.arange(8), "B": list("aabbbcc")})
В [140]: dff.groupby("B").filter(лямбда x: len(x) > 2)
Выход[140]:
А Б
2 2 б
3 3 б
4 4 б
5 5 б
В качестве альтернативы, вместо того, чтобы отбрасывать группы-нарушители, мы можем вернуть лайк-индексированные объекты, в которых заполняются группы, не прошедшие фильтр с NaN.
В [141]: dff.groupby("B").filter(лямбда x: len(x) > 2, dropna=False)
Выход[141]:
А Б
0 нн нн нн
1 нан нан нан
2 2,0 б
3 3,0 б
4 4,0 б
5 5,0 б
6 НН НН
7 нен нано
Для фреймов данных с несколькими столбцами фильтры должны явно указывать столбец в качестве критерия фильтра.
В [142]: dff["C"] = np.arange(8)
В [143]: dff.groupby("B").filter(lambda x: len(x["C"]) > 2)
Исход[143]:
А Б В
2 2 б 2
3 3 б 3
4 4 б 4
5 5 б 5
Примечание
Некоторые функции при применении к объекту groupby будут действовать как фильтр на входе, возвращая
уменьшенная форма оригинала (и потенциально исключающая группы), но с неизменным индексом. Передача
Передача as_index=False не повлияет на эти методы преобразования.
Например: голова, хвост.
В [144]: dff.groupby("B").head(2)
Исход[144]:
А Б В
0 0 а 0
1 1 а 1
2 2 б 2
3 3 б 3
6 6 в 6
7 7 в 7
Отправка на методы экземпляра
При выполнении агрегации или преобразования вы можете просто вызвать метод экземпляра для каждой группы данных. Это довольно легко сделать, передав лямбда функции:
В [145]: grouped = df.сгруппировать("А")
В [146]: grouped.agg(лямбда x: x.std())
Исход[146]:
КОМПАКТ ДИСК
А
бар 0,181231 1,366330
фу 0,5 0,884785
Но это довольно многословно и может быть неаккуратно, если вам нужно передать дополнительные аргументы. Используя немного хитрости метапрограммирования, GroupBy теперь имеет возможность «распределять» вызовы методов по группам:
В [147]: grouped.std()
Исход[147]:
КОМПАКТ ДИСК
А
бар 0,181231 1,366330
фу 0.5 0,884785
На самом деле здесь происходит то, что создается оболочка функции. сгенерировано. При вызове он принимает любые переданные аргументы и вызывает функцию
с любыми аргументами в каждой группе (в приведенном выше примере
сгенерировано. При вызове он принимает любые переданные аргументы и вызывает функцию
с любыми аргументами в каждой группе (в приведенном выше примере std функция). Затем результаты объединяются в стиле agg .
и преобразовать (фактически используется применить для определения склейки, задокументировано
следующий). Это позволяет выполнять некоторые операции довольно лаконично:
В [148]: tsdf = pd.кадр данных(
.....: np.random.randn (1000, 3),
.....: index=pd.date_range("1/1/2000", периоды=1000),
.....: столбцы = ["A", "B", "C"],
.....: )
.....:
В [149]: tsdf.iloc[::2] = np.nan
В [150]: grouped = tsdf.groupby(lambda x: x.year)
В [151]: grouped.fillna(method="pad")
Выход[151]:
А Б В
01.01.2000 NaN NaN NaN
02.01.2000 -0,353501 -0,080957 -0,876864
03.01.2000 -0,353501 -0,080957 -0,876864
04.01.2000 0,050976 0,044273 -0.559849
05.01.2000 0,050976 0,044273 -0,559849
... ... ... ...
22 сентября 2002 г. 0,005011 0,053897 -1,026922
23 сентября 2002 г. 0,005011 0,053897 -1,026922
24.09.2002 -0,456542 -1,849051 1,559856
25 сентября 2002 г. -0,456542 -1,849051 1,559856
2002-09-26 1,123162 0,354660 1,128135
[1000 строк x 3 столбца]
 0,005011 0,053897 -1,026922
23 сентября 2002 г. 0,005011 0,053897 -1,026922
24.09.2002 -0,456542 -1,849051 1,559856
25 сентября 2002 г. -0,456542 -1,849051 1,559856
2002-09-26 1,123162 0,354660 1,128135
[1000 строк x 3 столбца]
0,005011 0,053897 -1,026922
23 сентября 2002 г. 0,005011 0,053897 -1,026922
24.09.2002 -0,456542 -1,849051 1,559856
25 сентября 2002 г. -0,456542 -1,849051 1,559856
2002-09-26 1,123162 0,354660 1,128135
[1000 строк x 3 столбца]
В этом примере мы разбили набор временных рядов на годовые фрагменты. затем независимо вызвал fillna на группы.
Методы nlargest и nsalest работают с группами стилей серии :
В [152]: s = pd.Серия([9, 8, 7, 5, 19, 1, 4.2, 3.3])
В [153]: g = pd.Series(list("abababab"))
В [154]: gb = s.groupby(g)
В [155]: gb.nlargest(3)
Исход[155]:
а 4 19,0
0 9,0
2 7,0
б 1 8,0
3 5,0
7 3.3
тип: float64
В [156]: gb.nsmalest(3)
Исход[156]:
а 6 4,2
2 7,0
0 9,0
б 5 1,0
7 3.3
3 5,0
тип: float64
гибкий
применяется Некоторые операции над сгруппированными данными могут не соответствовать ни агрегату, ни
преобразовать категории.Или вы можете просто захотеть, чтобы GroupBy сделал вывод, как объединить
результаты. Для них используйте функцию
Для них используйте функцию apply , которую можно заменить
как для , так и для агрегирования и преобразования во многих стандартных случаях использования. Тем не мение, применить может обрабатывать некоторые исключительные случаи использования, например:
В [157]: df
Вышли[157]:
А Б В Г
0 foo один -0,575247 1,346061
1 бар один 0,254161 1,511763
2 foo два -1,143704 1,627081
3 бар три 0.215897 -0,9
4 фу два 1,193555 -0,441652
5 бар два -0,077118 1,211526
6 foo один -0,408530 0,268520
7 foo три -0,862495 0,024580
В [158]: grouped = df.groupby("A")
# также можно просто вызвать .describe()
В [159]: grouped["C"].apply(lambda x: x.describe())
Вышли[159]:
А
количество баров 3.000000
среднее значение 0,130980
стандарт 0.181231
мин -0,077118
25% 0,069390
...
фу мин -1.143704
25% -0,862495
50%-0.575247
75% -0,408530
максимум 1.193555
Имя: C, длина: 16, dtype: float64
Размер возвращаемого результата также может измениться:
В [160]: grouped = df.3 0,828287 4 0,194158 0,037697
 groupby('A')['C']
В [161]: def f(group):
.....: вернуть pd.DataFrame({'исходный': группа,
.....: 'униженный': группа - group.mean()})
.....:
В [162]: grouped.apply(f)
Исход[162]:
оригинал унижен
0 -0,575247 -0,215962
1 0,254161 0,123181
2 -1,143704 -0,784420
3 0.2
0 0,321438 0,103323
1 0,493496 0,243538
2 0,139505 0,019462
3 0,
groupby('A')['C']
В [161]: def f(group):
.....: вернуть pd.DataFrame({'исходный': группа,
.....: 'униженный': группа - group.mean()})
.....:
В [162]: grouped.apply(f)
Исход[162]:
оригинал унижен
0 -0,575247 -0,215962
1 0,254161 0,123181
2 -1,143704 -0,784420
3 0.2
0 0,321438 0,103323
1 0,493496 0,243538
2 0,139505 0,019462
3 0,Примечание
apply может действовать как редуктор, преобразователь, функция фильтра или , в зависимости от того, что ему передается.
Итак, в зависимости от выбранного пути и того, что именно вы группируете. Таким образом, сгруппированные столбцы могут быть включены в
вывод, а также установить индексы.
Подобно агрегатам с пользовательскими функциями, результирующий тип dtype будет отражать тип
применить функцию.Если результаты из разных групп имеют разные dtypes, то
общий dtype будет определяться так же, как конструкция DataFrame .
Ускоренные процедуры Numba
Если Numba установлена как необязательная зависимость, преобразование и совокупных методов поддерживают engine='numba' и engine_kwargs аргументов. См. Повышение производительности с помощью Numba для общего использования аргументов.
и соображения производительности.
См. Повышение производительности с помощью Numba для общего использования аргументов.
и соображения производительности.
Сигнатура функции должна начинаться с значений, индекс ровно как данные, принадлежащие каждой группе
в будут переданы значения , а индекс группы будет передан в индекс .
Предупреждение
При использовании engine='numba' внутренне не будет "возврата". Группа
данные и групповой индекс будут переданы в виде массивов NumPy пользовательской функции JIT, и никакие
будут опробованы альтернативные попытки выполнения.
Другие полезные функции
Автоматическое исключение «мешающих» столбцов
Снова рассмотрим пример DataFrame, который мы рассматривали:
В [167]: df
Вышли[167]:
А Б В Г
0 foo один -0,575247 1,346061
1 бар один 0,254161 1,511763
2 foo два -1,143704 1,627081
3 бар три 0,215897 -0,9
4 фу два 1,193555 -0,441652
5 бар два -0,077118 1,211526
6 foo один -0,408530 0,268520
7 foo три -0,862495 0.
024580
 024580
024580
Предположим, мы хотим вычислить стандартное отклонение, сгруппированное по A столбец. Есть небольшая проблема, а именно то, что нас не волнуют данные в
столбец B . Мы называем это столбцом «неприятности». Если прошло
функция агрегации не может быть применена к некоторым столбцам, проблемные столбцы
будет (молча) брошен. Таким образом, это не представляет никаких проблем:
В [168]: df.groupby("A").std()
Исход[168]:
КОМПАКТ ДИСК
А
бар 0.181231 1.366330
фу 0,5 0,884785
Обратите внимание, что df.groupby('A').colname.std(). более эффективен, чем df.groupby('A').std().colname , поэтому, если результат функции агрегирования
интересен только для одного столбца (здесь colname ), он может быть отфильтрован до с применением функции агрегирования.
Примечание
Любой столбец объекта, даже если он содержит числовые значения, такие как Десятичный объектов, рассматривается как «неприятные» столбцы. Они исключены из
агрегатные функции автоматически в groupby.
Они исключены из
агрегатные функции автоматически в groupby.
Если вы хотите включить десятичные или объектные столбцы в агрегацию с другие не мешающие типы данных, вы должны сделать это явно.
В [169]: из десятичного импорта Decimal
В [170]: df_dec = pd.DataFrame(
.....: {
.....: "id": [1, 2, 1, 2],
.....: "int_column": [1, 2, 3, 4],
.....: "dec_column": [
.....: Десятичный ("0,50"),
.....: Десятичный ("0.15"),
.....: Десятичный ("0,25"),
.....: Десятичный ("0,40"),
.....: ],
.....: }
.....: )
.....:
# Десятичные столбцы могут быть явно суммированы сами по себе...
В [171]: df_dec.groupby(["id"])[["dec_column"]].sum()
Исход[171]:
dec_column
я бы
1 0,75
2 0,55
# ...но нельзя комбинировать со стандартными типами данных, иначе они будут исключены
В [172]: df_dec.groupby(["id"])[["int_column", "dec_column"]].sum()
Исход[172]:
int_column
я бы
1 4
2 6
# Использовать .Функция agg для агрегирования стандартных и «неприятных» типов данных.
# в то же время
В [173]: df_dec.groupby(["id"]).agg({"int_column": "sum", "dec_column": "sum"})
Вышли[173]:
int_column dec_column
я бы
1 4 0,75
2 6 0,55
 # в то же время
В [173]: df_dec.groupby(["id"]).agg({"int_column": "sum", "dec_column": "sum"})
Вышли[173]:
int_column dec_column
я бы
1 4 0,75
2 6 0,55
# в то же время
В [173]: df_dec.groupby(["id"]).agg({"int_column": "sum", "dec_column": "sum"})
Вышли[173]:
int_column dec_column
я бы
1 4 0,75
2 6 0,55
Обработка (не)наблюдаемых категорийных значений
При использовании группировщика категорий (как одного группировщика или как части нескольких группировщиков) наблюдаемое ключевое слово определяет, следует ли возвращать декартово произведение всех возможных значений группировщиков ( Observed=False ) или только тех
наблюдаемые морские окуни ( Observed=True ).
Показать все значения:
В [174]: pd.Series([1, 1, 1]).groupby( .....: pd.Categorical(["а", "а", "а"], категории=["а", "б"]), наблюдаемый=ложь .....: ).считать() .....: Вышли[174]: 3 б 0 тип: int64
Показать только наблюдаемые значения:
В [175]: pd.Series([1, 1, 1]).groupby( .....: pd.Categorical(["а", "а", "а"], категории=["а", "б"]), наблюдаемый=Истина .
 ....: ).считать()
.....:
Вышли[175]:
3
тип: int64
....: ).считать()
.....:
Вышли[175]:
3
тип: int64
Возвращаемый dtype группы будет всегда включать все категорий, которые были сгруппированы.
В [176]: с = ( .....: pd.Серия([1, 1, 1]) .....: .groupby(pd.Categorical(["а", "а", "а"], категории=["а", "б"]), наблюдаемые=ложь) .....: .считать() .....: ) .....: В [177]: s.index.dtype Out[177]: CategoricalDtype(categories=['a', 'b'], order=False)
Обработка группы NA и NaT
Если в ключе группировки есть какие-либо значения NaN или NaT, они будут автоматически исключаются. Другими словами, никогда не будет «группы АН» или «Группа НАТ».В старых версиях панд такого не было, но пользователи были в любом случае отказываться от группы АН (и поддерживать ее было головная боль реализации).
Группировка с упорядоченными факторами
Категориальные переменные, представленные как экземпляр класса pandas Категориальный можно использовать как групповые ключи. Если да, то порядок уровней сохранится:
Если да, то порядок уровней сохранится:
В [178]: данные = pd.Series(np.random.randn(100)) В [179]: factor = pd.qcut(data, [0, 0,25, 0,5, 0,75, 1.0]) В [180]: data.groupby(factor).mean() Выход[180]: (-2,645, -0,523] -1,362896 (-0,523, 0,0296] -0,260266 (0,0296, 0,654] 0,361802 (0,654, 2,21] 1,073801 тип: float64
Группировка со спецификацией группировщика
Возможно, вам потребуется указать немного больше данных для правильной группировки. Ты сможешь
используйте pd.Grouper для обеспечения этого локального управления.
В [181]: импорт даты и времени
В [182]: df = pd.DataFrame(
.....: {
.....: "Ветвь": "А А А А А А А Б".расколоть(),
.....: "Покупатель": "Карл Марк Карл Карл Джо Джо Джо Карл".split(),
.....: "Количество": [1, 3, 5, 1, 8, 1, 9, 3],
.....: "Дата": [
.....: datetime.datetime(2013, 1, 1, 13, 0),
.....: datetime.datetime(2013, 1, 1, 13, 5),
.....: datetime.datetime(2013, 10, 1, 20, 0),
. ....: datetime.datetime(2013, 10, 2, 10, 0),
.....: datetime.datetime(2013, 10, 1, 20, 0),
.....: дата/время.дата и время (2013, 10, 2, 10, 0),
.....: datetime.datetime(2013, 12, 2, 12, 0),
.....: datetime.datetime(2013, 12, 2, 14, 0),
.....: ],
.....: }
.....: )
.....:
В [183]: дф
Исход[183]:
Филиал Покупатель Количество Дата
0 А Карл 1 01.01.2013 13:00:00
1 Марк 3 01.01.2013 13:05:00
2 А Карл 5 01.10.2013 20:00:00
3 А Карл 1 2013-10-02 10:00:00
4 А Джо 8 2013-10-01 20:00:00
5 А Джо 1 2013-10-02 10:00:00
6 А Джо 9 2013-12-02 12:00:00
7 Б Карл 3 2013-12-02 14:00:00
 ....: datetime.datetime(2013, 10, 2, 10, 0),
.....: datetime.datetime(2013, 10, 1, 20, 0),
.....: дата/время.дата и время (2013, 10, 2, 10, 0),
.....: datetime.datetime(2013, 12, 2, 12, 0),
.....: datetime.datetime(2013, 12, 2, 14, 0),
.....: ],
.....: }
.....: )
.....:
В [183]: дф
Исход[183]:
Филиал Покупатель Количество Дата
0 А Карл 1 01.01.2013 13:00:00
1 Марк 3 01.01.2013 13:05:00
2 А Карл 5 01.10.2013 20:00:00
3 А Карл 1 2013-10-02 10:00:00
4 А Джо 8 2013-10-01 20:00:00
5 А Джо 1 2013-10-02 10:00:00
6 А Джо 9 2013-12-02 12:00:00
7 Б Карл 3 2013-12-02 14:00:00
....: datetime.datetime(2013, 10, 2, 10, 0),
.....: datetime.datetime(2013, 10, 1, 20, 0),
.....: дата/время.дата и время (2013, 10, 2, 10, 0),
.....: datetime.datetime(2013, 12, 2, 12, 0),
.....: datetime.datetime(2013, 12, 2, 14, 0),
.....: ],
.....: }
.....: )
.....:
В [183]: дф
Исход[183]:
Филиал Покупатель Количество Дата
0 А Карл 1 01.01.2013 13:00:00
1 Марк 3 01.01.2013 13:05:00
2 А Карл 5 01.10.2013 20:00:00
3 А Карл 1 2013-10-02 10:00:00
4 А Джо 8 2013-10-01 20:00:00
5 А Джо 1 2013-10-02 10:00:00
6 А Джо 9 2013-12-02 12:00:00
7 Б Карл 3 2013-12-02 14:00:00
Сгруппировать по определенному столбцу с нужной частотой.Это похоже на повторную выборку.
В [184]: df.groupby([pd.Grouper(freq="1M", key="Date"), "Покупатель"]).sum()
Исход[184]:
Количество
Дата Покупатель
31.01.2013 Карл 1
Марк 3
2013-10-31 Карл 6
Джо 9
2013-12-31 Карл 3
Джо 9
У вас есть неоднозначная спецификация в том, что у вас есть именованный индекс и столбец
это могут быть потенциальные груперы.
В [185]: df = df.set_index("Дата")
В [186]: df["Date"] = df.index + pd.offsets.MonthEnd(2)
В [187]: df.groupby([pd.Grouper(freq="6M", key="Date"), "Покупатель"]).sum()
Вышли[187]:
Количество
Дата Покупатель
2013-02-28 Карл 1
Марк 3
28.02.2014 Карл 9
Джо 18
В [188]: df.groupby([pd.Grouper(freq="6M", level="Date"), "Покупатель"]).sum()
Вышли[188]:
Количество
Дата Покупатель
31.01.2013 Карл 1
Марк 3
2014-01-31 Карл 9
Джо 18
Взятие первых строк каждой группы
Точно так же, как для DataFrame или Series, вы можете вызывать голову и хвост для группы:
В [189]: df = pd.DataFrame([[1, 2], [1, 4], [5, 6]], столбцы = ["A", "B"])
В [190]: дф
Выход[190]:
А Б
0 1 2
1 1 4
2 5 6
В [191]: g = df.groupby("A")
В [192]: g.head(1)
Исход[192]:
А Б
0 1 2
2 5 6
В [193]: g.tail(1)
Исход[193]:
А Б
1 1 4
2 5 6
Показывает первые или последние n строк из каждой группы.
Занятие n-й строки каждой группы
Чтобы выбрать из DataFrame или Series n-й элемент, используйте й() . Это метод сокращения, и
вернет одну строку (или ни одной строки) для каждой группы, если вы передадите int для n:
В [194]: df = pd.DataFrame([[1, np.nan], [1, 4], [5, 6]], столбцы = ["A", "B"])
В [195]: g = df.groupby("A")
В [196]: g.nth(0)
Исход[196]:
Б
А
1 NaN
5 6,0
В [197]: g.nth(-1)
Вышли[197]:
Б
А
1 4,0
5 6,0
В [198]: g.nth(1)
Вышли[198]:
Б
А
1 4,0
Если вы хотите выбрать n-й ненулевой элемент, используйте ключ dropna . Для DataFrame это должно быть либо «любой» , либо «все» , как если бы вы перешли к dropna:
# nth(0) совпадает с g.первый()
В [199]: g.nth(0, dropna="любой")
Вышли[199]:
Б
А
1 4,0
5 6,0
В [200]: g.first()
Выход[200]:
Б
А
1 4,0
5 6,0
# nth(-1) совпадает с g.last()
В [201]: g.nth(-1, dropna="any") # NaN обозначают исчерпание группы при использовании dropna
Выход[201]:
Б
А
1 4,0
5 6,0
В [202]: g. last()
Выход[202]:
Б
А
1 4,0
5 6,0
В [203]: g.B.nth(0, dropna="все")
Выход[203]:
А
1 4,0
5 6,0
Имя: B, dtype: float64
 last()
Выход[202]:
Б
А
1 4,0
5 6,0
В [203]: g.B.nth(0, dropna="все")
Выход[203]:
А
1 4,0
5 6,0
Имя: B, dtype: float64
last()
Выход[202]:
Б
А
1 4,0
5 6,0
В [203]: g.B.nth(0, dropna="все")
Выход[203]:
А
1 4,0
5 6,0
Имя: B, dtype: float64
Как и в случае с другими методами, при передаче as_index=False будет достигнута фильтрация, возвращающая сгруппированную строку.
В [204]: df = pd.DataFrame([[1, np.nan], [1, 4], [5, 6]], columns=["A", "B"])
В [205]: g = df.groupby("A", as_index=False)
В [206]: g.nth(0)
Исход[206]:
А Б
0 1 NaN
2 5 6,0
В [207]: g.nth(-1)
Исход[207]:
А Б
1 1 4,0
2 5 6,0
Вы также можете выбрать несколько строк из каждой группы, указав несколько значений n в виде списка целых чисел.
В [208]: business_dates = pd.date_range(start="01.04.2014", end="30.06.2014", freq="B")
В [209]: df = pd.DataFrame(1, index=business_dates, столбцы=["a", "b"])
# получить индекс первой, четвертой и последней даты для каждого месяца
В [210]: df.groupby([df.index.year, df.index.month]).nth([0, 3, -1])
Выход[210]:
а б
2014 4 1 1
4 1 1
4 1 1
5 1 1
5 1 1
5 1 1
6 1 1
6 1 1
6 1 1
Перечислить элементы группы
Чтобы увидеть порядок, в котором каждая строка появляется в своей группе, используйте cumcount метод:
В [211]: dfg = pd.
 DataFrame (список ("aaabba"), столбцы = ["A"])
В [212]: дфг
Выход[212]:
А
0 а
1 год
2 часа
3 б
4 б
5 а
В [213]: dfg.groupby("A").cumcount()
Выход[213]:
0 0
1 1
2 2
3 0
4 1
5 3
тип: int64
В [214]: dfg.groupby("A").cumcount(возрастание=ложь)
Выход[214]:
0 3
1 2
2 1
3 1
4 0
5 0
тип: int64
DataFrame (список ("aaabba"), столбцы = ["A"])
В [212]: дфг
Выход[212]:
А
0 а
1 год
2 часа
3 б
4 б
5 а
В [213]: dfg.groupby("A").cumcount()
Выход[213]:
0 0
1 1
2 2
3 0
4 1
5 3
тип: int64
В [214]: dfg.groupby("A").cumcount(возрастание=ложь)
Выход[214]:
0 3
1 2
2 1
3 1
4 0
5 0
тип: int64
Перечислить группы
Чтобы увидеть порядок групп (в отличие от порядка строк
в группе, заданной cumcount ), вы можете использовать нгруппа() .
Обратите внимание, что номера, присвоенные группам, соответствуют порядку, в котором группы будут видны при переборе объекта groupby, а не порядок их первого наблюдения.
В [215]: dfg = pd.DataFrame(list("aaabba"), columns=["A"])
В [216]: дфг
Выход[216]:
А
0 а
1 год
2 часа
3 б
4 б
5 а
В [217]: dfg.groupby("A").ngroup()
Выход[217]:
0 0
1 0
2 0
3 1
4 1
5 0
тип: int64
В [218]: dfg.groupby("A").ngroup(возрастание=ложь)
Выход[218]:
0 1
1 1
2 1
3 0
4 0
5 1
тип: int64
Заговор
Groupby также работает с некоторыми методами построения графиков. Например, предположим, что мы
подозреваю, что некоторые функции в DataFrame могут различаться по группам, в этом случае
значения в столбце 1, где группа «B», в среднем на 3 выше.
Например, предположим, что мы
подозреваю, что некоторые функции в DataFrame могут различаться по группам, в этом случае
значения в столбце 1, где группа «B», в среднем на 3 выше.
В [219]: np.random.seed(1234) В [220]: df = pd.DataFrame(np.random.randn(50, 2)) В [221]: df["g"] = np.random.choice(["A", "B"], size=50) В [222]: df.loc[df["g"] == "B", 1] += 3
Мы можем легко визуализировать это с помощью диаграммы:
В [223]: df.groupby("g").boxplot()
Выход[223]:
AxesSubplot (0.1,0,15;0,363636x0,75)
Оси BSubplot (0,536364, 0,15; 0,363636x0,75)
тип: объект
Результатом вызова boxplot является словарь, ключами которого являются значения
нашей группировки столбца г («А» и «Б»). Значения результирующего словаря
может управляться ключевым словом return_type блока boxplot .
Дополнительную информацию см. в документации по визуализации.
Предупреждение
По историческим причинам df. не эквивалентен
до  groupby("g").boxplot()
groupby("g").boxplot() дф.блокплот(by="g") . Смотрите здесь для
объяснение.
Функция трубопровода вызывает
Аналогично функциям, предоставляемым DataFrame и серии , функции
которые принимают объектов GroupBy , могут быть объединены в цепочку с использованием метода pipe для
обеспечить более чистый и читаемый синтаксис. Чтобы прочитать о .pipe в общих чертах,
глянь сюда.
Сочетание .groupby и .pipe часто полезно, когда вам нужно повторно использовать
Группировать по объектам.
В качестве примера представьте, что у вас есть DataFrame со столбцами для магазинов, продуктов,
выручка и количество проданных товаров. Мы хотели бы сделать групповой расчет цен (т. е. выручка/количество) на магазин и на продукт. Мы могли бы сделать это в
многоступенчатая операция, но выражая ее в терминах трубопровода, можно сделать
код более читабелен. Сначала устанавливаем данные:
Сначала устанавливаем данные:
В [224]: n = 1000
В [225]: df = pd.DataFrame(
.....: {
.....: "Магазин": np.random.choice(["Магазин_1", "Магазин_2"], n),
.....: "Товар": np.random.choice(["Товар_1", "Товар_2"], n),
.....: "Доход": (np.random.random(n) * 50 + 10).round(2),
.....: "Количество": np.random.randint(1, 10, размер=n),
.....: }
.....: )
.....:
В [226]: df.head(2)
Выход[226]:
Количество доходов от продаж в магазине
0 Магазин_2 Товар_1 26.12 1
1 Магазин_2 Товар_1 28,86 1
Теперь, чтобы найти цены для каждого магазина/продукта, мы можем просто сделать:
В [227]: ( .....: df.groupby(["Магазин", "Товар"]) .....: .pipe(лямбда-группа: группа.Доход.сумма() / группа.Количество.сумма()) .....: .unstack() .....: .раунд 2) .....: ) .....: Выход[227]: Продукт Продукт_1 Продукт_2 Магазин Магазин_1 6,82 7,05 Магазин_2 6,30 6,64
Трубопровод также может быть выразительным, когда вы хотите доставить сгруппированный объект к некоторым произвольная функция, например:
В [228]: def mean(groupby): .
 ....: вернуть groupby.значит()
.....:
В [229]: df.groupby(["Магазин", "Продукт"]).pipe(mean)
Выход[229]:
Доход Количество
Магазин продукта
Store_1 Product_1 34.622727 5.075758
Товар_2 35.482815 5.029630
Магазин_2 Продукт_1 32,972837 5,237589
Товар_2 34.684360 5.224000
....: вернуть groupby.значит()
.....:
В [229]: df.groupby(["Магазин", "Продукт"]).pipe(mean)
Выход[229]:
Доход Количество
Магазин продукта
Store_1 Product_1 34.622727 5.075758
Товар_2 35.482815 5.029630
Магазин_2 Продукт_1 32,972837 5,237589
Товар_2 34.684360 5.224000
, где означает, что берет объект GroupBy и находит среднее значение дохода и количества.
столбцы соответственно для каждой комбинации Store-Product. Функция означает .
быть любой функцией, которая принимает объект GroupBy; .pipe пройдет GroupBy
object в качестве параметра в указанную вами функцию.
Примеры
Перегруппировка по фактору
Перегруппируйте столбцы DataFrame в соответствии с их суммой и суммируйте агрегированные столбцы.
В [230]: df = pd.DataFrame({"a": [1, 0, 0], "b": [0, 1, 0], "c": [1, 0, 0], " г": [2, 3, 4]})
В [231]: дф
Выход[231]:
а б в г
0 1 0 1 2
1 0 1 0 3
2 0 0 0 4
В [232]: df. groupby(df.sum(), axis=1).sum()
Выход[232]:
1 9
0 2 2
1 1 3
2 0 4
 groupby(df.sum(), axis=1).sum()
Выход[232]:
1 9
0 2 2
1 1 3
2 0 4
groupby(df.sum(), axis=1).sum()
Выход[232]:
1 9
0 2 2
1 1 3
2 0 4
Многостолбцовая факторизация
Используя ngroup() , мы можем извлечь
информацию о группах аналогично factorize() (как описано
далее в API изменения формы), но который применяется
естественно для нескольких столбцов смешанного типа и разных
источники.Это может быть полезно в качестве промежуточного шага, подобного категориальному.
в обработке, когда отношения между строками группы более
важно, чем их содержание, или в качестве входных данных для алгоритма, который только
принимает целочисленное кодирование. (Для получения дополнительной информации о поддержке в
pandas для полных категориальных данных, см. Категориальные
введение и
Документация API.)
В [233]: dfg = pd.DataFrame({"A": [1, 1, 2, 3, 2], "B": list("aaaba")})
В [234]: дфг
Выход[234]:
А Б
0 1 а
1 1 а
2 2 а
3 3 б
4 2 а
В [235]: дфг.groupby(["A", "B"]).ngroup()
Выход[235]:
0 0
1 0
2 1
3 2
4 1
тип: int64
В [236]: dfg. groupby(["A", [0, 0, 0, 1, 1]]).ngroup()
Исход[236]:
0 0
1 0
2 1
3 3
4 2
тип: int64
 groupby(["A", [0, 0, 0, 1, 1]]).ngroup()
Исход[236]:
0 0
1 0
2 1
3 3
4 2
тип: int64
groupby(["A", [0, 0, 0, 1, 1]]).ngroup()
Исход[236]:
0 0
1 0
2 1
3 3
4 2
тип: int64
Группировка по индексатору для «пересчета» данных
Повторная выборка создает новые гипотетические выборки (повторные выборки) из уже существующих наблюдаемых данных или из модели, которая генерирует данные. Эти новые образцы аналогичны ранее существовавшим образцам.
Для повторной выборки для работы с индексами, не подобными дате и времени, можно использовать следующую процедуру.
В следующих примерах df.index // 5 возвращает двоичный массив, который используется для определения того, что выбирается для операции группировки.
Примечание
В приведенном ниже примере показано, как мы можем понизить выборку путем объединения выборок в меньшее количество выборок. Здесь, используя df.index // 5 , мы собираем выборки в ячейки. Применяя функцию std() , мы объединяем информацию, содержащуюся во многих выборках, в небольшое подмножество значений, которое является их стандартным отклонением, тем самым уменьшая количество выборок.
В [237]: df = pd.DataFrame(np.random.randn(10, 2))
В [238]: дф
Исход[238]:
0 1
0 -0,793893 0,321153
1 0,342250 1,618906
2 -0,975807 1,918201
3 -0,810847 -1,405919
4 -1,977759 0,461659
5 0,730057 -1,316938
6 -0,751328 0,528290
7 -0,257759 -1,081009
8 0,505895 -1,701948
9 -1,006349 0,020208
В [239]: df.index // 5
Out[239]: Int64Index([0, 0, 0, 0, 0, 1, 1, 1, 1, 1], dtype='int64')
В [240]: df.groupby(df.index // 5).std()
Выход[240]:
0 1
0 0.823647 1.312912
1 0,760109 0,942941
Возврат серии для распространения имен
Сгруппировать столбцы DataFrame, вычислить набор показателей и вернуть именованный ряд. Имя серии используется в качестве имени индекса столбца. Это особенно полезно в сочетании с операциями изменения формы, такими как укладка, в которой имя индекса столбца будет использоваться как имя вставленного столбца:
В [241]: df = pd.DataFrame(
.....: {
.....: "а": [0, 0, 0, 0, 1, 1, 1, 1, 2, 2, 2, 2],
..... : "б": [0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1],
.....: "с": [1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0],
.....: "д": [0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1],
.....: }
.....: )
.....:
В [242]: определение вычисления_метрики(х):
.....: результат = {"b_sum": x["b"].sum(), "c_mean": x["c"].mean()}
.....: вернуть pd.Series (результат, имя = "метрика")
.....:
В [243]: результат = df.groupby("a").apply(compute_metrics)
В [244]: результат
Выход[244]:
показатели b_sum c_mean
а
0 2.0 0,5
1 2,0 0,5
2 2,0 0,5
В [245]: result.stack()
Выход[245]:
метрика
0 b_sum 2.0
c_mean 0,5
1 б_сум 2.0
c_mean 0,5
2 б_сум 2.0
c_mean 0,5
тип: float64
 : "б": [0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1],
.....: "с": [1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0],
.....: "д": [0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1],
.....: }
.....: )
.....:
В [242]: определение вычисления_метрики(х):
.....: результат = {"b_sum": x["b"].sum(), "c_mean": x["c"].mean()}
.....: вернуть pd.Series (результат, имя = "метрика")
.....:
В [243]: результат = df.groupby("a").apply(compute_metrics)
В [244]: результат
Выход[244]:
показатели b_sum c_mean
а
0 2.0 0,5
1 2,0 0,5
2 2,0 0,5
В [245]: result.stack()
Выход[245]:
метрика
0 b_sum 2.0
c_mean 0,5
1 б_сум 2.0
c_mean 0,5
2 б_сум 2.0
c_mean 0,5
тип: float64
: "б": [0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1],
.....: "с": [1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0],
.....: "д": [0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1],
.....: }
.....: )
.....:
В [242]: определение вычисления_метрики(х):
.....: результат = {"b_sum": x["b"].sum(), "c_mean": x["c"].mean()}
.....: вернуть pd.Series (результат, имя = "метрика")
.....:
В [243]: результат = df.groupby("a").apply(compute_metrics)
В [244]: результат
Выход[244]:
показатели b_sum c_mean
а
0 2.0 0,5
1 2,0 0,5
2 2,0 0,5
В [245]: result.stack()
Выход[245]:
метрика
0 b_sum 2.0
c_mean 0,5
1 б_сум 2.0
c_mean 0,5
2 б_сум 2.0
c_mean 0,5
тип: float64
Совет №1 — Разделите большие классы на более мелкие группы
В сообщении блога на прошлой неделе мы представили 10 советов для успешного синхронного сеанса. Сегодня мы собираемся изучить совет № 1: Рассмотрим разделение больших классов на две более короткие и меньшие группы.
Физический класс предлагает учащимся естественные возможности для передвижения, независимо от того, объединяются ли они в группы или подходят к доске. Это не относится к виртуальным классам, где ученики сидят и смотрят на экран. Даже когда вам предлагают веселые, творческие онлайн-действия, все равно трудно сидеть и концентрировать внимание в течение длительного периода времени. Поэтому выгодно, чтобы виртуальные уроки были относительно короткими. Один из способов добиться этого — разделить большие классы на два.Если размер класса уменьшится, учитель сможет быстрее освоить больше материала.
Но это не единственное преимущество небольших классов, особенно в виртуальном классе. Обстановка виртуального класса поначалу может показаться довольно искусственной и пугающей, когда один человек говорит за раз, и все смотрят на него. Чтобы задать вопрос или сделать комментарий в такой обстановке, может потребоваться много нервов, в результате чего некоторые студенты отходят на второй план. Однако, разделив учащихся на две меньшие группы, учителя могут решить эту проблему.
Однако, разделив учащихся на две меньшие группы, учителя могут решить эту проблему.
Меньшие группы, как правило, менее опасны, поэтому учащиеся более уверенно участвуют в обсуждениях в классе. По мере того, как все больше студентов участвуют, делятся своими взглядами и идеями, уроки становятся более интерактивными. Меньший размер группы также позволяет выслушать больше учеников, даже если урок укорочен. Интимная среда виртуального класса также способствует сотрудничеству и обучению навыкам построения команды.
Учителя также получают выгоду от небольших классов.Они могут легче отслеживать успеваемость учащихся, выявлять пробелы в их знаниях и предоставлять немедленную помощь и обратную связь. С меньшим количеством учеников учителям легче персонализировать уроки и заставлять учеников работать в своем собственном темпе.
Если вы не можете разделить свой класс на две части и учить каждую группу отдельно, есть альтернативный вариант. Вы можете начать занятия со всем классом, а затем разделить учащихся на группы, отправив их в отдельные «комнаты для обсуждения» или «комнаты для чатов», доступные в вашем программном обеспечении для виртуального класса. Ближе к концу урока вы можете снова собрать всех вместе и попросить представителей выступить в качестве представителей своих групп.
Ближе к концу урока вы можете снова собрать всех вместе и попросить представителей выступить в качестве представителей своих групп.
На следующей неделе мы обсудим , как подготовить учащихся к онлайн-уроку , изучая совет № 2 из наших «10 советов для успешного синхронного сеанса». Увидимся позже!
разделить на две группы - Перевод на английский - примеры русский
Эти примеры могут содержать нецензурные слова, основанные на вашем поиске.
Эти примеры могут содержать разговорные слова на основе вашего поиска.
Нам нужно разделить на две группы , выживших и остальных.
Члены Morning Musume обычно делятся на две группы , которые бросают вызов другим японским знаменитостям, чтобы принять участие в серии игр, по одной или более для каждого из вышеупомянутых углов.
Затем мы разделились на две группы .
Его члены разделились на две группы .
Тысячу пациентов с сердечными заболеваниями разделили на две группы .
Ну, а теперь предлагаю разделиться на две группы .
В 1977 году первая партия была разделена на две группы .
Они были разбиты на две группы : 4 парня против 3 девушек.
Хорошо, наши основные силы будут , разделенными на две группы .
Там он разделился на две группы .
Незадолго до своего поражения в Египте Исмаилии разделились на две группы , названные низаритами и мусталитами.
Петроградские рабочие были разделены на две группы .
Их было пять человек, разбитых на две группы .
Они разделились на две группы , направляясь к каждому участку.
После еды мы делимся на две группы .
Восемь команд разбиты на две группы по четыре человека.
Затем эти специалисты были разделены на две группы .
Комиссия разделилась на две группы для выполнения своей программы наблюдения.
Con el objeto de cumplir su programa de observación de las prisiones, la Comisión se dividió en dos grupos .Команды были разделены на две группы .
Миура вместе добежали до середины Эстафеты, где разделились на две группы .
Планирование на случай пандемии: не забудьте разделить персонал на местах на отдельные группы
Поскольку мы продолжаем наблюдать эскалацию случаев заражения вирусом в Висконсине, очень важно, чтобы банки, которые еще не сделали этого, начали немедленно разделять персонал на местах на группы или уровней, а также иметь планы по обеспечению постоянного укомплектования персоналом всех открытых филиалов. Вполне возможно, что некоторые сотрудники банка заразятся вирусом, и если у одного из сотрудников будет положительный результат на COVID-19, все сотрудники, которые находились рядом с этим человеком в отделении, должны самостоятельно пройти карантин в течение 14 дней.Департамент здравоохранения штата Висконсин рекомендует отстранить от работы сотрудников, которым сообщают, что они подвержены среднему или высокому риску заражения, на 14 дней, в течение которых они должны следить за симптомами и/или лихорадкой. Работодатели с сотрудниками, у которых был диагностирован COVID-19, но у которых не было никаких симптомов, могут прекратить домашнюю изоляцию, когда прошло не менее семи дней с даты их первого положительного диагностического теста на COVID-19 и у них не было последующего заболевания. См. руководство CDC.
Вполне возможно, что некоторые сотрудники банка заразятся вирусом, и если у одного из сотрудников будет положительный результат на COVID-19, все сотрудники, которые находились рядом с этим человеком в отделении, должны самостоятельно пройти карантин в течение 14 дней.Департамент здравоохранения штата Висконсин рекомендует отстранить от работы сотрудников, которым сообщают, что они подвержены среднему или высокому риску заражения, на 14 дней, в течение которых они должны следить за симптомами и/или лихорадкой. Работодатели с сотрудниками, у которых был диагностирован COVID-19, но у которых не было никаких симптомов, могут прекратить домашнюю изоляцию, когда прошло не менее семи дней с даты их первого положительного диагностического теста на COVID-19 и у них не было последующего заболевания. См. руководство CDC.
Чтобы обеспечить постоянное укомплектование персоналом, чтобы вам не приходилось закрывать место, влияющее на ваших клиентов, вы должны разделить свой персонал на разные группы или уровни, чтобы не все ваши ключевые сотрудники могли быть затронуты, если один сотрудник заболеет вирус. Некоторые банки разделили свой персонал на две или три отдельные группы людей, так что одна и та же небольшая группа работает в отделении одну неделю, а следующая небольшая группа работает в отделении на следующей неделе. Еще одно предложение состоит в том, чтобы иметь ограниченную небольшую группу, постоянно работающую в каждом отделении, но иметь еще один уровень персонала, который не находится в этом месте, готовый взять на себя управление конкретным отделением в случае, если кто-то заболеет. Другие связываются с вышедшими на пенсию сотрудниками, чтобы привлекать их по мере необходимости только в рамках планирования пандемии.Все банки должны планировать это потенциальное обстоятельство; однако это особенно важно для небольших банков с очень небольшим количеством офисов и уже скудным персоналом.
Некоторые банки разделили свой персонал на две или три отдельные группы людей, так что одна и та же небольшая группа работает в отделении одну неделю, а следующая небольшая группа работает в отделении на следующей неделе. Еще одно предложение состоит в том, чтобы иметь ограниченную небольшую группу, постоянно работающую в каждом отделении, но иметь еще один уровень персонала, который не находится в этом месте, готовый взять на себя управление конкретным отделением в случае, если кто-то заболеет. Другие связываются с вышедшими на пенсию сотрудниками, чтобы привлекать их по мере необходимости только в рамках планирования пандемии.Все банки должны планировать это потенциальное обстоятельство; однако это особенно важно для небольших банков с очень небольшим количеством офисов и уже скудным персоналом.
Автор, Эрик Скрам
Почему движение за права женщин разделилось из-за 15-й поправки к поправке (Служба национальных парков США)
Элизабет Кэди Стэнтон (слева) и Сьюзен Б. Энтони (справа) около 1900 года.
Энтони (справа) около 1900 года.Wikimedia Commons
Когда в 1865 году завершилась Гражданская война в США, защитники прав женщин сочли, что пришло время добиваться права голоса.Женщины в значительной степени отказались от своей политической активности во время войны в интересах содействия военным усилиям Союза. Они работали разнорабочими, медсестрами на поле боя и сиделками в своих семьях. Теперь казалось, что пришло время предоставить женщинам избирательное право в знак благодарности за эту военную службу. Самой влиятельной организацией, продвигающей избирательное право женщин в то время, была Американская ассоциация равных прав (AERA), в которую входили активисты-ветераны, такие как Люси Стоун, Сьюзен Б.Энтони, Элизабет Кэди Стэнтон, Лукреция Мотт, Соджорнер Трут и Фредерик Дуглас.
С 1866 по 1869 год все штаты, проводившие референдум об избирательном праве женщин, отвергли эту идею. Одна крупная победа произошла, когда губернатор территории Вайоминг подписал в 1869 году закон о предоставлении права голоса женщинам в этом районе. Тем не менее активисты были разочарованы продолжающейся борьбой и рассмотрели идею внесения поправки в конституцию, чтобы обеспечить избирательные права женщин по всей стране.Однако еще две неудачи на федеральном уровне еще больше осложнили эти усилия. Когда в 1868 году была ратифицирована 14-я поправка, в Разделе 2 говорилось, что, если какой-либо штат не позволит части своего мужского населения голосовать, основа представительства этого штата в Конгрессе будет сокращена пропорционально его общей численности взрослого мужского населения. Другими словами, включение в Конституцию слова «мужской» создало видимость того, что право голоса принадлежит только мужчинам. В том же году предложенная 15-я поправка призвала положить конец дискриминации избирателей по признаку расы, но такая формулировка не была добавлена для прекращения дискриминации по признаку пола.
Тем не менее активисты были разочарованы продолжающейся борьбой и рассмотрели идею внесения поправки в конституцию, чтобы обеспечить избирательные права женщин по всей стране.Однако еще две неудачи на федеральном уровне еще больше осложнили эти усилия. Когда в 1868 году была ратифицирована 14-я поправка, в Разделе 2 говорилось, что, если какой-либо штат не позволит части своего мужского населения голосовать, основа представительства этого штата в Конгрессе будет сокращена пропорционально его общей численности взрослого мужского населения. Другими словами, включение в Конституцию слова «мужской» создало видимость того, что право голоса принадлежит только мужчинам. В том же году предложенная 15-я поправка призвала положить конец дискриминации избирателей по признаку расы, но такая формулировка не была добавлена для прекращения дискриминации по признаку пола.
Когда президент Улисс С. Грант вступил в должность и выступил в поддержку 15-й поправки в 1869 году, идея всеобщего избирательного права в Американской ассоциации равных прав начала рушиться. С одной стороны, некоторые лидеры, такие как Стоун и Дуглас, поддержали 15-ю поправку и утверждали, что это «час негров» и что право голоса чернокожих мужчин должно стоять на первом месте. После ратификации 15-й поправки AERA сможет настаивать на внесении отдельной поправки в отношении избирательного права женщин. С другой стороны, видные голоса, такие как Энтони и Стэнтон, утверждали, что любая поправка к конституции, которая не предоставляет женщинам избирательного права, неприемлема.Если кто и заслуживал голоса, так это «образованные» белые женщины. Стэнтон, в частности, утверждал, что афроамериканцы не знают законов и обычаев политической системы США, и что это «серьезный вопрос, не лучше ли нам отойти в сторону и увидеть, как «Самбо» войдет в королевство [гражданских прав] первым. " Афроамериканские женщины, такие как Фрэнсис Эллен Уоткинс Харпер, раскритиковали обе стороны дебатов за игнорирование уникального положения чернокожих женщин в Америке. Во время Национального женского съезда в 1866 году Харпер заявила, что «вы, белые женщины, говорите здесь о правах.
С одной стороны, некоторые лидеры, такие как Стоун и Дуглас, поддержали 15-ю поправку и утверждали, что это «час негров» и что право голоса чернокожих мужчин должно стоять на первом месте. После ратификации 15-й поправки AERA сможет настаивать на внесении отдельной поправки в отношении избирательного права женщин. С другой стороны, видные голоса, такие как Энтони и Стэнтон, утверждали, что любая поправка к конституции, которая не предоставляет женщинам избирательного права, неприемлема.Если кто и заслуживал голоса, так это «образованные» белые женщины. Стэнтон, в частности, утверждал, что афроамериканцы не знают законов и обычаев политической системы США, и что это «серьезный вопрос, не лучше ли нам отойти в сторону и увидеть, как «Самбо» войдет в королевство [гражданских прав] первым. " Афроамериканские женщины, такие как Фрэнсис Эллен Уоткинс Харпер, раскритиковали обе стороны дебатов за игнорирование уникального положения чернокожих женщин в Америке. Во время Национального женского съезда в 1866 году Харпер заявила, что «вы, белые женщины, говорите здесь о правах. Я говорю об ошибках. Я, цветная женщина, получила в этой стране образование, благодаря которому я почувствовала себя на месте Измаила: моя рука против каждого мужчины и рука каждого мужчины против меня».
Я говорю об ошибках. Я, цветная женщина, получила в этой стране образование, благодаря которому я почувствовала себя на месте Измаила: моя рука против каждого мужчины и рука каждого мужчины против меня».
Переломный момент для AERA пришел во время своего третьего ежегодного собрания 12 мая 1869 г. Фредерик Дуглас поднялся, чтобы выступить, и заявил, что использование Стентоном расистских выражений и стереотипов было оскорбительным. Он продолжил, утверждая, что «я не понимаю, как кто-то может притворяться, что настойчивость в предоставлении избирательного бюллетеня женщине, как негру.У нас это вопрос жизни и смерти, по крайней мере, в пятнадцати штатах Союза [в отношении бывших рабовладельческих штатов]. Когда за женщинами, потому что они женщины, охотятся в Нью-Йорке и Новом Орлеане. . . когда им угрожает опасность, что их дома сожгут над их головами; когда их детям не разрешают ходить в школу; тогда у них будет срочная необходимость получить бюллетени, равные нашим».
Сьюзен Б. Энтони ответила Дугласу. умный в первую очередь.Если разум, справедливость и нравственность должны иметь приоритет в правительстве, пусть вопрос о женщинах поднимается первым, а вопрос о неграх — последним. . . Мистер Дуглас говорит о несправедливостях негра; но со всеми оскорблениями, от которых он сегодня страдает, он не поменялся бы своим полом и не занял бы место Элизабет Кэди Стэнтон». Вторя более ранним комментариям Фрэнсис Эллен Уоткинс Харпер, Sojourner Truth утверждал, что «есть большой переполох по поводу того, что цветные мужчины получают свои права». , но ни слова о цветной женщине, и если цветные мужчины получат свои права, а не цветные женщины - свои, то это будет плохое время.Начали проявляться недостатки организации.
Энтони ответила Дугласу. умный в первую очередь.Если разум, справедливость и нравственность должны иметь приоритет в правительстве, пусть вопрос о женщинах поднимается первым, а вопрос о неграх — последним. . . Мистер Дуглас говорит о несправедливостях негра; но со всеми оскорблениями, от которых он сегодня страдает, он не поменялся бы своим полом и не занял бы место Элизабет Кэди Стэнтон». Вторя более ранним комментариям Фрэнсис Эллен Уоткинс Харпер, Sojourner Truth утверждал, что «есть большой переполох по поводу того, что цветные мужчины получают свои права». , но ни слова о цветной женщине, и если цветные мужчины получат свои права, а не цветные женщины - свои, то это будет плохое время.Начали проявляться недостатки организации.
Американская ассоциация равных прав распалась после встречи 1869 года, и движение за права женщин разделилось на две отдельные группы, которые больше никогда не воссоединялись в течение 19 века. Стэнтон и Энтони создали Национальную ассоциацию избирательного права женщин, которая выступала за поправку к конституции, касающуюся избирательного права женщин, и занималась другими политическими вопросами, такими как законы о разводе и движение за воздержание. Руководили организацией также исключительно женщины.Стоун и Джулия Уорд Хоу организовали Американскую ассоциацию избирательного права женщин, которая выступала за законы штата, разрешающие избирательное право женщин, но в основном воздерживалась от других политических вопросов. Мужчины также занимали руководящие должности в этой организации. Хотя историк Салли Макмиллен признает, что раскол в движении за права женщин, скорее всего, был неизбежен, она утверждает, что движение за избирательные права было отложено до начала 20 века отчасти из-за разделения и разногласий среди руководства движения.Дебаты по поводу 15-й поправки играют решающую роль в объяснении того, как возникла эта напряженность после Гражданской войны.
Руководили организацией также исключительно женщины.Стоун и Джулия Уорд Хоу организовали Американскую ассоциацию избирательного права женщин, которая выступала за законы штата, разрешающие избирательное право женщин, но в основном воздерживалась от других политических вопросов. Мужчины также занимали руководящие должности в этой организации. Хотя историк Салли Макмиллен признает, что раскол в движении за права женщин, скорее всего, был неизбежен, она утверждает, что движение за избирательные права было отложено до начала 20 века отчасти из-за разделения и разногласий среди руководства движения.Дебаты по поводу 15-й поправки играют решающую роль в объяснении того, как возникла эта напряженность после Гражданской войны.
Служба национальных парков, «Обзор избирательного права женщин».
Салли Макмиллен, Сенека-Фолс и истоки движения за права женщин . Нью-Йорк: Издательство Кембриджского университета, 2009.
Элизабет Кэди Стэнтон, Сьюзен Б. Энтони и Матлида Джослин Гейдж, История избирательного права женщин, том II: 1861-1876 . Рочестер, Нью-Йорк: Чарльз Манн, 1887, стр.382-390.
Энтони и Матлида Джослин Гейдж, История избирательного права женщин, том II: 1861-1876 . Рочестер, Нью-Йорк: Чарльз Манн, 1887, стр.382-390.
Как быстро разделить одну группу контактов на две группы через Outlook VBA
Многие пользователи просят быстро разделить слишком большую группу контактов вместо копирования и удаления участников вручную. Эта статья научит, как использовать VBA для разделения группы контактов на две группы одним щелчком мыши.
Возможно, у вас довольно большая группа контактов в Outlook. В частности, эта контактная группа состоит из нескольких членов. В таких случаях вам может быть немного сложно их организовать.Поэтому вы можете разделить его. Обычно вы можете разделить метод, описанный в моей старой статье — «Как разделить большую группу контактов Outlook». Но это значит слишком хлопотно. Поэтому здесь мы представим второй метод, который может разбить группу на две в один миг.
Быстрое разделение одной группы контактов на две группы
- Для начала запустите программу Outlook.
- Затем в главном окне Outlook нажмите клавиши «Alt + F11», чтобы открыть редактор VBA.
- Далее в окне «Microsoft Visual Basic для приложений» нужно открыть неиспользуемый модуль.
- Затем в этот модуль необходимо скопировать следующий код VBA.

Sub SplitOneContactGroupIntoTwo()
Dim objSourceContactGroup как Outlook.DistListItem
Dim lMemberCount As Long
Dim objNewContactGroup как Outlook.DistListItem
Dim objMember как Outlook.recipient
Dim objTempMail как Outlook.MailItem
'Получить исходную контактную группу
Выберите приложение «Дело».Активвиндов.Класс
Дело olExplorer
Установите objSourceContactGroup = ActiveExplorer.Selection.Item(1)
Дело olInspector
Установите objSourceContactGroup = ActiveInspector.CurrentItem
Конец выбора
'Создать новую контактную группу
Установить objNewContactGroup = Application.CreateItem(olDistributionListItem)
lMemberCount = objSourceContactGroup. MemberCount
Для i = 1 в objSourceContactGroup.количество участников
Установить objMember = objSourceContactGroup.GetMember(i)
'Удалить определенное количество участников из исходной группы
'И добавить их в новую группу
Если я < lMemberCount / 2 Тогда
Установите objTempMail = Application.CreateItem(olMailItem)
objTempMail.Recipients.Add (objMember.Address)
objNewContactGroup.AddMembers objTempMail.Recipients
objSourceContactGroup.RemoveMember objMember
objSourceContactGroup.Сохранять
objTempMail.Close olDiscard
Конец, если
Следующий
objNewContactGroup.Display
Конец суб  MemberCount
Для i = 1 в objSourceContactGroup.количество участников
Установить objMember = objSourceContactGroup.GetMember(i)
'Удалить определенное количество участников из исходной группы
'И добавить их в новую группу
Если я < lMemberCount / 2 Тогда
Установите objTempMail = Application.CreateItem(olMailItem)
objTempMail.Recipients.Add (objMember.Address)
objNewContactGroup.AddMembers objTempMail.Recipients
objSourceContactGroup.RemoveMember objMember
objSourceContactGroup.Сохранять
objTempMail.Close olDiscard
Конец, если
Следующий
objNewContactGroup.Display
Конец суб
MemberCount
Для i = 1 в objSourceContactGroup.количество участников
Установить objMember = objSourceContactGroup.GetMember(i)
'Удалить определенное количество участников из исходной группы
'И добавить их в новую группу
Если я < lMemberCount / 2 Тогда
Установите objTempMail = Application.CreateItem(olMailItem)
objTempMail.Recipients.Add (objMember.Address)
objNewContactGroup.AddMembers objTempMail.Recipients
objSourceContactGroup.RemoveMember objMember
objSourceContactGroup.Сохранять
objTempMail.Close olDiscard
Конец, если
Следующий
objNewContactGroup.Display
Конец суб - После этого вы можете выйти из текущего окна, нажав значок «X» в правом верхнем углу.
- Позже, для удобного доступа в будущем, вам лучше добавить новый проект VBA на панель быстрого доступа, которую можно заполнить в «Параметры Outlook».
- В конце концов, вы можете сделать снимок:

- Во-первых, вы можете выбрать или открыть группу контактов, которую нужно разделить.
- Затем нажмите кнопку только что добавленного макроса на панели быстрого доступа.
- Сразу же Outlook переместит около половины участников исходной группы в новую группу контактов.
Использование мощного средства исправления в случае повреждения Outlook
Хотя Outlook может похвастаться множеством функций, он все же не может быть свободен от ошибок и сбоев. Как правило, в случае серьезного сбоя данные Outlook могут быть повреждены. Таким образом, он поставляется с внутренним инструментом восстановления Scanpst.Однако, если ваш PST-файл серьезно скомпрометирован, этот инструмент не поможет. Поэтому всегда рекомендуется иметь под рукой более надежный инструмент, например DataNumen Outlook Repair.
Введение автора:
Ширли Чжан — эксперт по восстановлению данных в компании DataNumen, Inc. , которая является мировым лидером в области технологий восстановления данных, включая программные продукты для восстановления mdf и Outlook Repair. Для получения дополнительной информации посетите www.datanumen.com
, которая является мировым лидером в области технологий восстановления данных, включая программные продукты для восстановления mdf и Outlook Repair. Для получения дополнительной информации посетите www.datanumen.com
Разделить список
Разделение списка позволяет вам взять существующий список и разбить его на более мелкие части (разделенные группы).Например, вы можете взять список из 100 тысяч контактов и разделить на три части. подсписки, каждый из которых содержит процент от исходного списка (список A: 50%, список B 25% и список C 25%). Контакты из исходного списка будут случайным образом распределены по сплиту. группы.
Об этой задаче
Вы можете разделить список на 5 отдельных списков (разделов), каждый со своим случайным группа контактов из исходного списка.
Чтобы разделить список:
Процедура
- Перейти к .
- Нажмите на название списка, который вы хотите разделить.
- Щелкните Разделить.
- Дополнительно: При необходимости измените имя внутреннего списка.
По умолчанию текстовое поле «Внутреннее имя» уже заполнено внутренним именем
оригинальный список. Любые последующие разбиения списка будут использовать указанное здесь внутреннее имя. За
например, Мой список - Разделить A , где Мой список внутреннее имя.
Изменение внутреннего имени на разделенной странице списка не меняется внутреннее имя, присвоенное исходному списку при его создании.
- Дополнительно: Щелкните в текстовом поле «Имя» для каждой группы разделения списка и измените
его имя.
Этот текст будет отображаться после внутреннего имени, используемого для разделения списка. Например, если у вас было внутреннее имя Example List , и вы изменили группу A имя сплита на Split Number One , будет отображаться сплит группы A (в таблицы, средства выбора списков и т.